

I’ve been working for the last 9 months on a new project, which I would summarise as: next generation information modelling for the age of AI. I’ve called it SPLASH, which stands for Standard Pattern Library for Advanced Science and Healthcare, mainly because I liked the acronym. SPLASH aims to provide semantic scalability across all domains, not just healthcare (where I have worked for the last 25 years), and extends the openEHR domain modelling approach known as archetypes, via the use of ontology marking and extensive code-generation.
Due to the advances in AI-assisted code generation, the result is modelling from the domain to solution, largely bypassing the majority of manual software development activities.
What do the new information models look like? They are generic and entirely oriented to a next generation form of archetyping, as used in openEHR. There are some elements of the core representation which provide interesting examples, for example the fine-grained representation of all data.
Fine-grained Data Representation
SPLASH has a general theory that high level information structures are ‘epistemic’, meaning that they represent business or other human concepts such as ‘observation’ or ‘person’ or ‘encounter’. But below all such structures is a common fine-grained representation of details, whose shapes are governed by archetypes, workflow models or other domain knowledge artifacts. The elements are marked with codes from ontologies, enabling machine interpretation of the semantics.
openEHR people will be familiar with the concept of generic fine-grain representation using the CLUSTER and ELEMENT classes, shown below in UML.
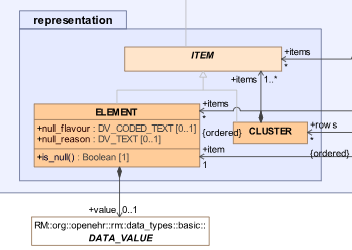
This leads to structures like the following in archetypes (and therefore data):
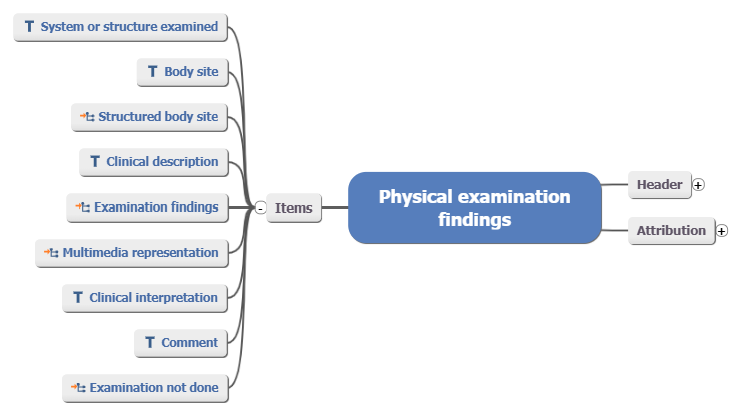
The above structure is a CLUSTER, and each of the items on the left are more CLUSTERs or ELEMENTs. Note that to represent the body site of the examination requires two nodes, one for a single coded term (‘Body site’, an ELEMENT) and one for a detailed description of body location (‘Structure body site’, a CLUSTER slot).
In the SPLASH model universe, the model of detailed data takes a different form, show below.
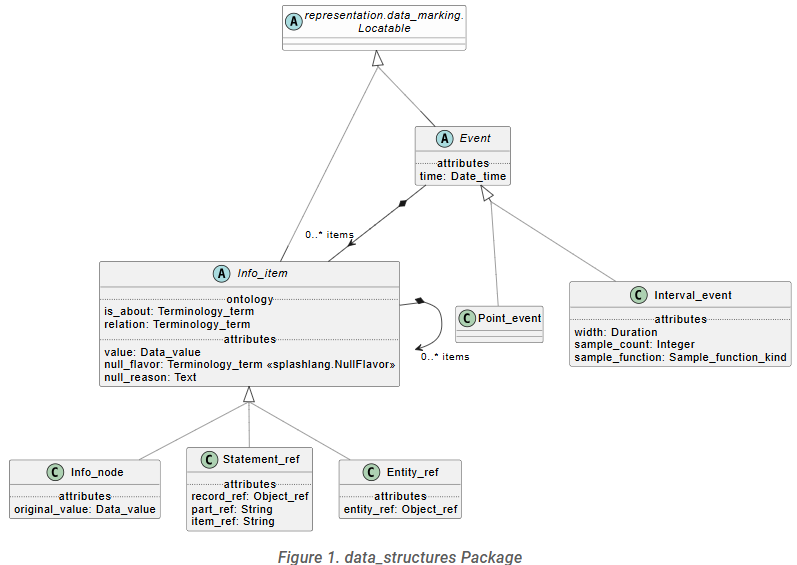
This pattern merges the ‘value’ of ELEMENT and ‘items’ of CLUSTER into a single class, Info_item. This allows for fractal representation of data, which is how we need to be able to represent reality.
Fractal Data Representation
Whether a particular real world entity is described as a logical atom (e.g. using a coded term), or in great detail is often not known at design time. For this reason, SPLASH provides a model of fine-grained data that allows any data node to describe an entity in reality both as a simple atom, and/or with any amount of detailed ‘fractal’ substructure.
An example of such information is ‘body site’, which can be described both with a single term (e.g. from SNOMED CT) and a detailed structure. A patient description of an area of abdominal pain (such as resulting from as-yet undiagnosed appendicitis) could be recorded as:
- the code
snomed_ct::48544008|Structure of right lower quadrant of abdomen (body structure)|; - and/or with a detailed structure, such as:
- reference point =
snomed_ct::39583001|right anterior superior iliac spine|; - direction = “3 O’clock”
- distance = 10 cm
- reference point =
A physician (aided by the appropriate application) might record both. (At a later encounter, if the problem is in fact appendicitis and it is becoming more acute, the physician will possibly record the location as “McBurney’s point”, i.e. 1/3 the distance from the right hip and umbilicus).
The instance structure for the above representation, where both value and items are instantiated is:

Similarly, a mole might be described using the SNOMED CT code 314066006|fleshy mole|, or a detailed physical description including diameter, colour, recency etc.
Almost any aspect of the real world may be described in a single atom of data that effectively summarises it, and/or a detailed multi-part description. Which is used depends on the use. Using both might make sense on the basis that different subsequent consumers of the data (such as analytics software and human users) might want one or the other form.
The principle also applies to purely informational entities. For example, person address could be recorded as a single line of text, (potentially including newline characters), which functions well for humans, printing envelopes, and free text matching software. It also obviates difficulties in knowing the correct structured form, e.g. according to the US postal database. However, the structured form is preferred for most computational use, and is usually the one captured on government, travel and e-commerce sites. The single text string form might be generated from the structured form and both recorded.
Entity References
The SPLASH model of fine-grained data solves other needs.
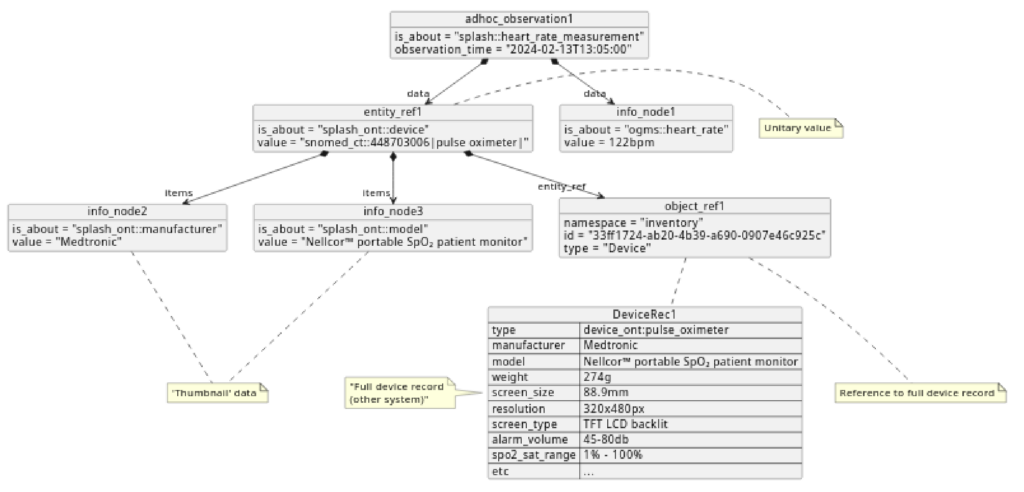
A very common need not solved in mainstream IT is to reference an external entity, such as a Person (e.g. the physician who wrote this note), a Device (e.g. used to examine the eyes), or an Encounter (a record maintained by hospital administration) but also capture a few of its data elements inline – a ‘data thumbnail’ – i.e. at the source of the reference. For example we may want a logical reference to the physician Dr Paul Tarsus, which is maintained in a system (often of a state jurisdiction) where his full professional record is maintained, but also to capture the name, profession, state registered, and medical board number, i.e. a short record [“Dr Paul Tarsus”, “Pediatrician”, “Westphalia, Germany”, “123456789”].
Today, capturing these extra details might be done with extra ad hoc database columns or attributes that cannot be systematically relied upon computationally. The default means of entity referencing is just simple foreign keys, allowing no data thumbnail.
In openEHR, entity referencing is done in at least three different ways, none entirely satisfactory (and since I created all of them in the original models, I accept the blame…)
In the model here, the class Entity_ref provides a systematic way to represent a true reference, plus a thumbnail data set for any referenced external information entity. The thumbnail can be archetyped to suit common purposes.
We still want to record the simple unitary description of the target entity as well, typically a coded term representing its kind, e.g. ‘obstetric ultrasound machine’ or ‘pediatric surgeon’.
Thus, in summary, for externally represented entities, we want to be able to record any or all of the following:
- unitary: a single data value is used to describe the entity. This is often a coded term that indicates what kind of thing the entity is, e.g.
snomed_ct::448703006|pulse oximeter|. It could also be a single string containing a house address; - thumbnail: a small collection of useful details about the object, e.g. for a device, its manufacturer, model, and unique device identifier; for a doctor, name and medical registration id;
- reference: reference to a separately maintained database record or other resource that potentially fully describes the object, or its type.
The properties value (inherited), items (inherited), and entity_ref provide these three representations. The value property is mandatory, and either, both or none of the other two may be used. Note that the items property, which is used for a full representation of an inline item in an instance of Info_node is conveniently reused here to represent the data thumbnail.
The following example shows an Entity_ref instance representing a reference from clinical data (heart rate measurement Observation) to a Device (pulse oximeter).
Conclusion
Above I have shown just a small sample of design thinking from the SPLASH model ecosystem. It is advancing rapidly, and addresses areas outside the clinical, including administration, billing, CRM, inventory, geospatial and more.
An interesting question is of course whether such next generation ideas can be retrofitted to today’s openEHR. The astute will see was that the above pattern can in principle be incorporated into openEHR without breaking it, but not quite without breaking today’s archetypes or data. There are ways to deal with that. A topic for another post!
Wonderful to see this out in the open now! I think an early use case can be for analytical copy of openEHR CDR content in knowledge graph to make reasoning with AI more efficient. 1:1 mapping at least FROM current openEHR version to SPLASH would be necessary to support.
Question: Sometimes there is an algorithmic way to go from detailed multi-property (fractal) representation to more coarse grained representation (like the SNOMED CT codes above. Could such algorithms be stored/represented in the Template and depending on system either be used at runtime before storing or later at analysis time if preferred?
I take issue with your statement that “Almost any aspect of the real world may be described in a single atom of data that effectively summarises it, and/or a detailed multi-part description.”
I can’t see that only one reference is needed for an entity.
For example an oximeter has
Manufacturer > Manufacturer’ batch records > batch number>components
> Manufacturers development records> development history
Usage history> location
> patients
Maintenance> history records>
> schedule
etc.
All of which have related structures
An oximeter archetype could name structures that could be used to store/extract its data.
An implementation would provide the relevant access methods.
That’s the point of fractal representation: for many users, just summarising the instrument used with a code ‘pulse oximeter’ is sufficient. For other users, the substructure of the device type, and also of the instance (i.e. things like usage, cleaning, upgrading etc) are needed.
This pattern allows just the simple summary form, or summary+detail. It’s up to the archetype modellers as to what they want.
THanks Tom – you are touching on areas that will make their way forward. Love the SPLASH! Always on the horizon! AI can make a big difference to many aspects of data, engineering and health care. We probably need to consider what will have the most benefit for patients, their carers and health professionals, without being too disruptive. Keep it up!