
The Unified Modelling Language aka UML has been around for 22 years, as you can see from the OMG UML page. We use it extensively to publish the openEHR specifications, in a similar way to many other organisations. Developers often use it for whiteboard brain-storming. But hardly anyone uses it for its original purpose: formal modelling of software leading to code, ideally with round-tripping. And this is despite the availability of excellent UML tools. Architects these days tend to limit their use of UML to package diagrams and a few illustrative class diagrams, while developers tend to go straight to code or use tools that pretty-print extracted textual forms of software such as swagger and apiary.
In openEHR, we publish specifications, so graphical representation of formal models is important. UML is still the only widely used graphical format, so we use it. However, to get around all its problems, I had to develop an alternative for static models, called Basic Meta-Model (BMM), to enable correct formal model representation for our tooling. This was not done lightly – we had to do it because UML does not represent the developer view of models correctly, and that’s the one we want. Worse, its serial form, XMI, is unreliable and unusable by humans or tools other then the creating UML tool. We also developed a UML extractor for the UML tool we use, to fix some of the problems it has, so we know a thing or two about UML under the covers. I have no doubt other organisations have resorted to similar fixes.
A few years ago I asked 8 senior software engineers at a meeting who was using a UML tool in their development work. A total of zero hands went up. And yet humans love pictures, so we should be using some sort of graphical modelling language. What went wrong for UML?
It’s a long story. Unlike many of the standards I have complained about for years in e-health, UML is a standard that ‘works’ and is implementable, at least in a concrete sense. This is undeniable due to the availability of dozens of UML tools, at least some of which do indeed, really and truly implement the UML standard. In openEHR, we use one of these, MagicDraw. This tool and at least one other, Rational Software Architect (RSA) implement all the details of the UML standard, and are well-engineered and maintained pieces of software with good support. (Note: I make no endorsement of any UML tool here, but as I need an examplar for this post, I will generally refer to MagicDraw for this purpose, due to our use of it in openEHR).
I want to note at the outset, that although I make a number of criticisms here, I take no pleasure in it. The OMG is an engineering-led standards community, and I am an engineer by training, and have sporadically been an OMG member and attended meetings. All the engineers I meet at OMG meetings are well-versed in mathematics, logic, architecture and many other IT sub-domains. They are serious people who can build real things.
UML was built by people like this – people like me in fact. People who, if let too long to work on a machine will build one that can fly to Mars, but can also, in a different operational mode be used for marine sonography and light shows for rock concerts. People obsessed with generality…
However – as a user of the standard, I have to look at it objectively, and that is the vein in which I have made this critique.
The UML standard is vastly over-complicated
The UML 2.x specifications are exceedingly complex: UML 2.2 was specified by two documents, ‘Superstructure’ (738pp) and ‘Infrastructure’ (224pp); the UML 2.5.1 specification that replaces both of these is only slightly smaller at 796 pages (see the OMG UML page for current specifications). The XMI 2.5 specification is correspondingly complex, which seems to have so far prevented reliable tool interoperability. If you are technical, it really is worth having a look at the UML 2.5.1 specification – ask yourself: is this how I would like to compute with static object model concepts in a modelling / programming environment? The answer is unlikely to be ‘yes’.
The primary problem with UML is something that was probably thought to be its stroke of genius: multiple levels of meta-models. Now, I like meta-models, and am very familiar with thinking in multiple levels of abstraction (although if the light is dim and I have started on a glass of nice shiraz, slightly less capable), so in principle this is a good thing – each ‘level’ of meta-model is expressed in a higher-level set of more general primitives. For this reason, there is a whole other 80-page standard called the Meta-Object Facility (MOF).
Now, right at the outset, there is a problem – UML and MOF are defined in terms of each other. To do meta-modelling properly, there is a golden rule: each level can only depend on the level below it; there can be no two-way dependencies through the meta-model stack. UML and MOF fail this test.
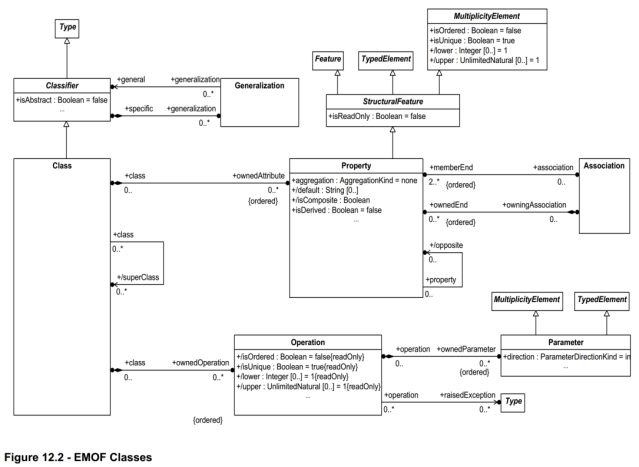
You will see the following model in the MOF, and you might think: great, nice and simple, I can see meta-types for Class, Property, Operation and so on – this seems very clear.
Unfortunately, things are not so simple. Firstly, this ‘model’ is just a greatly simplified view of meta-classes in the much larger UML standard; the actual meta-model is gigantic, over-general and obscure – below is just one part of the real model from the UML 2.5.1. PDF. If you start to look at it properly, the complexity will become obvious.
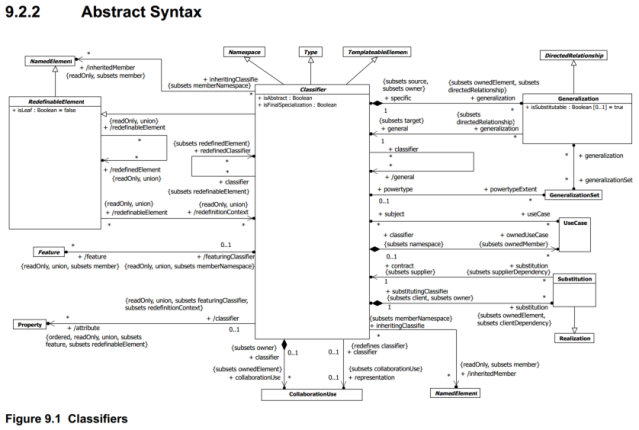
One feature visible here is the ubiquitous use of the ‘subsets’ feature of UML (which no-one ordinarily uses), which enables a more specialised version of a feature, say ‘Member’ to be redefined into multiple specialised features in a sub-class, e.g. ‘Property’, ‘Operation’ and ‘Reception’. This splitting of a named feature into multiple features of different names is not supported in any mainstream programming language, making its implementation difficult, but also reducing the comprehensibility of the UML meta-model.
An easier way to see how complex the UML meta-model is is via the online meta-model view tool available at OMG, called the NIST validator. Here is the link, starting at the meta-type Class. The following shows the inheritance flattened view of the Class meta-type – 50 properties:Now try an exercise. Imagine that in a concrete model you have a class Interval <T:Ordered> representing the generic class Interval with one formal generic parameter T that is constrained to be a descendant of the type Ordered. Try to traverse the model to find the ‘Ordered’, which is a type constraint on the generic parameter. You will discover endless staircases, corridors, dimly lit rooms, and will almost certainly wind up back where you started before getting anywhere near the goal.

By contrast, the location of this generic type constraint in the BMM is easy to find:
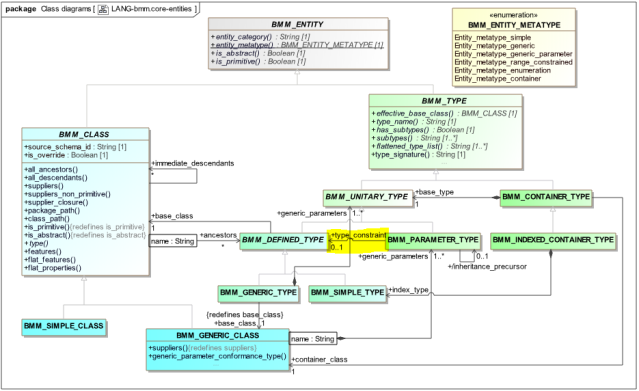
The BMM_CLASS meta-type equivalent of UML Class is shown below, in the form visible in IntelliJ from the openEHR Archie project implementation of BMM (22 properties):

This is by no means to claim that BMM is the definitive way to model the notion of Class, other approaches are certainly possible. However it is one way, and generally speaking has only 25-50% of the complexity of UML.
The quantity of classes and features is just one aspect of the complexity problem. The UML Class meta-type shown above is actually missing some of the features it should have, for example, proper type name and signature, such as Interval<T: Ordered>. Worse, since the meta-type Class in UML has to double as Type (the actual UML meta-class Type is trivial and useless), it should really have a number of other features.
UML tries to do too much
One ostensible reason for the complexity of the UML meta-model is to enable different types of concrete model to be expressed. The classic ‘static class model’ (exemplified by the UML diagrams above) is just one kind of UML model. Inside any decent UML tool you will find the ability to create ‘package diagrams’, ‘interaction diagrams’, ‘state diagrams’, ‘component diagrams’ and so on. Some of these diagrams are indeed useful, but the correct approach to defining a meta-model for each would have been to define a concrete, formal meta-model of the concepts specific to each. In the meta-model for a class diagram, meta-types representing various kinds of class, type and feature are needed. In a state diagram, formal representation of the concepts ‘state’, ‘transition’, nesting and so on are needed. Each type of diagram in fact represents a specific conceptual space, which needs its own specific model.
UML tries to define a single meta-model whose elements can be theoretically used to represent entities for 14 kinds of diagram. The result of this is that each kind of diagram is full of meta-classes and features whose purpose for that kind of model are obscure. It compounds the problem by mixing graphic elements in all over the place, which complicate the meta-model interface and makes details of the graphical visualisation of a model part of its formal description.
A far better approach would have been to:
- define a distinct meta-models for the few different kinds of model really needed – e.g. class model, state machine, interaction description;
- define a graphical language(s) as a separate layer.
UML has no formal language counter-part
The real problems of UML are to do with lack of formalisation. UML is defined in terms of the kind of diagrams it intends to define, without defining the reference semantics in any other way. This was recognised very early on, as evidenced by this quote from a 1999 paper on using formal methods to improve UML:
The UML architects justify their limited use of formal techniques by claiming that “the state of the practice in formal specifications does not yet address some of the more difficult language issues that UML introduces”. Our experiences with formalizing OO concepts indicate that this is not the case.
This referred to UML 1.1, but not much has changed in the intervening 20 years – all subsequent issues of the UML standard are still expressed in UML diagrams. I was unable to locate any papers from the last 15 years on the topic of using formal methods to improve UML and I suspect the topic has been abandoned.
The result is that UML is primarily just a diagramming notation, and does not make any serious attempt to formally define, for example, what a ‘type’ is, and how it is different from a ‘class’. It has meta-types such as Classifier that are only defined implicitly, i.e. by their relations with other abstract meta-model elements. This becomes quite problematic when one tries to establish the formal representation of say a partly closed generic type like HashMap<String, V>, which might be specified in the inheritance clause of some other class IndexedList<V>. This is really quite odd, because there is no lack of publications on formal type theory, and UML could have based its formal grammar on one.
Mostly what we get are not formal relations between formal elements, but diagrammatic relations.
UML mixes visual and conceptual elements
A good formal meta-model should contain only conceptual elements, with visual arrangements and diagramming represented as a separate layer. In UML we have a messy soup of visual and conceptual elements, which in the meta-model inherit from each other. An example is shown below – Section 11.2.2, Abstract Syntax [of Structured Classifiers]. Conceptual elements are marked with a blue X, graphical ones with red.

This approach creates a major problem: the formal definition of a model depends on how you happen to visualise it. If you visualise a property ‘inline’ within a class box, it is just a Property; if you visualise it as a line between the client and supplier class boxes, it is a Property and an Association; the association carries more meta-data not available in a pure Property. Associations can thus be ‘inherited’, which makes no sense conceptually. The effect of Associations can be seen in a UML tool:

The association / attribute conundrum also creates other problems: if you visualise classes A, B and C, with class A’s attributes of type B and C respectively as lines on diagram A, then association meta-objects will be created. If in another diagram you try to visualise class A with all its properties shown as attributes (i.e. inside the class box), the associations will be removed from the model, and the lines on the first diagram will just disappear. (It is unclear to me whether this is a formal intention of the UML specification, or just an unwelcome side-effect of its most obvious interpretation by too-builders).
If you want to prgrammatically process a UML model through an API (like the MagicDraw openAPI) or using the serial XMI format, you have to step around numerous constructs representing visual artefacts to get to the formal elements you want.
Graphical Usability
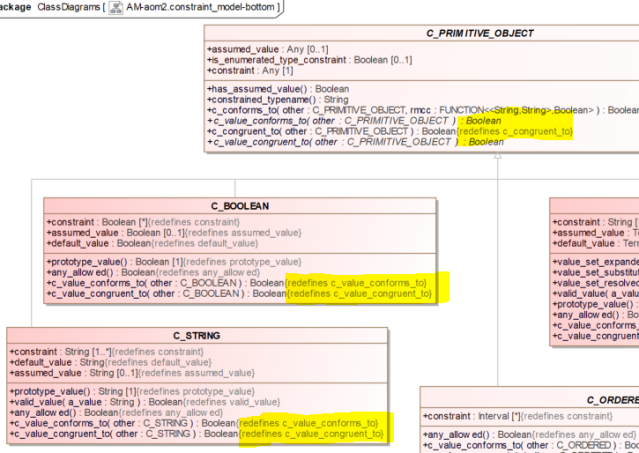
One of the more acceptable aspects of UML is that it does work pretty well as a visual notation for a lot of cases. However, even here, insufficient attention is paid to visual usability, or what today would be called ‘user experience’ (UX). Take the following example of an extract of a model in which descendant classes contain feature redefinitions, a very common feature of object models. UML diagrams this by adding longhand strings like ‘{redefines c_value_conforms_to}’ which forces many of the class boxes to be nearly twice the necessary width, and conveys no useful information, since the redefinition doesn’t change the name. A simple one-character symbol such as a Greek delta (Δ) would have been much better.
XMI is terrible
It’s hard to be kinder than that when talking about XMI. Now, to be fair, it does work, in the sense that a tool can save to it and read it in safely. This is what MagicDraw does – a model’s serial representation is inside any .mdzip file, and it is (to my knowledge) ‘proper’ XMI. There are two problems with XMI. One is that no two tools agree on how to implement it, so its function as ‘XML Model Exchange’ usually doesn’t work. If you don’t believe me, have a look at the number of variant flavours of XMI MagicDraw will generate – this is not a good sign – it means that the people at NoMagic have given up on the idea of just using one standard XMI, and have made built-in assumptions about different flavours of XMI for different tools.

Here’s the XMI export dialog for another tool, BOUML, that I used to use (not in MagicDraw’s league, but pretty decent, for what it was designed for, which was mainly C++ code generation):

As can be seen: 4 variants of UML 2.x (UML 1.x is a whole other menu option), and for UML 2.3, 9 options, including one (highlighted) that shows that Eclipse and everyone else don’t even agree on which end of a relation aggregation markers should go.
The second problem with XMI is that no human can possibly consider editing it, so human creation of model files is out of the question. Here is a bit of XMI, in case of doubt:
Is it possible or desirable for humans to be able to read or write model files? For us in e-health the answer is yes. The BMM format has a sister specification defining a persistence format called P_BMM, that is admittedly a bit ugly and perverse in places, but is nevertheless used in openEHR and HL7 to hand-edit models. Some real P_BMM files may be found on Github; here is a typical excerpt:

The above shows a class PLAN_DATA_CONTEXT with its properties. The BMM approach to this is by no means the only one. OMG’s own IDL is a better serial format than XMI, and Ecore’s Xcore also has something quite palatable. Our plan for the next generation of BMM serial format is something like IDL / Xcore. However: it has to be noted that neither of these properly represents all the semantics of generic (aka ‘template’) types – particularly through inheritance. This perennial problem is one reason we don’t just use something like Xcore or IDL outright. Generics can be gotten right – as we have done in BMM, mostly thanks to Bertrand Meyer’s wonderful language Eiffel, now sadly out of mainstream use.
Semantic Specifics
The above critique may seem somewhat abstract, and the reader might be wondering what concrete things are really broken in UML? Here are a few. These are not vague opinions or aesthetic concerns, these are things that we have to deal with in the UML model extractor that we wrote that generates formal class definitions for openEHR (example here). (Note: there are things I should go into here, such as the terrible idea of ‘data types’ as distinct from ‘composite types’, and also Enumerations, but … life is short).
Type is not distinguished from Class
In UML, the Type meta-type is defined as a String name, and has no structural semantics. In real modelling and programming languages however, Types are used in models to:
- define the type of a property;
- define formal type parameters in a generic class;
- define type(s) of inheritance ancestors of class definitions;
- determine conformance, which is a relation between types (not classes).
In addition, they specify the instantiable form of any object at runtime. By contrast, Classes are definitional artefacts. Types are entities generated from classes. More detail is provided in the BMM specification.
In UML, the lack of proper Types mostly manifests as an inability to represent generic / container types, and (open) generic parameter types in a way normal for a programmer. There is no simple way for example to say that Company.employees is of type List<Person> or that industrySectors is of type Set<IndustrySectorType>. All you have at your disposal is multiplicity and various constraints such as uniqueness.
Generic Types are incorrectly represented
In most modern programming languages, you can write:
public class MyFastThingList: List<Thing> { ... }
which means that the non-generic class MyFastList inherits from the generic type List<Thing>. But we could have also done either of these two things:
public class MyFastList<T>: List<T> { ... }
public class StringIndexedHash<V>: HashMap<String, V> { ... }The first is a generic class inheriting from a generic class; the second is a generic class inheriting from a partially closed generic type. Now, to get any of this right, you cannot avoid distinguishing formally between classes and types, and you also need a proper model of genericity, including open and closed type parameters, and how genericity functions through inheritance.
The lack of proper representation in UML means there is no easy way to model any of the above definitions. You can define a generic class, and you can then define another that inherits from it, but the UML meta-model doesn’t know about the notion of properties of the open generic type (typically ‘T’). To inherit from closed or partially closed generic types, you have to create fake classes with names like ‘HashMap<String,V>’, with generic parameter V, inherit from HashMap<K,V>, and then add a binding of the K type to String. Painful.
Another problem is that when traversing a model expressed in UML meta-model form, just obtaining a generic type name, rather than the simple class name is quite difficult.
Containment is Poorly Represented
The most common variety of generic type is of course the container. In 90% of mainstream programming, just three types do nearly all the containing:
List<T> // ArrayedList<T>, etc
Set<T> // ArrayedSet<T>, etc
Map<V,K> // HashMap<V,K>, Dictionary<V,K> etcThere are no such types in UML. You can create them yourself of course, but you are then stuck with the task of creating endless pseudo-classes representing all the types you actually want, i.e. List<String>, Set<Policy> etc. No-one does this because it is too painful. Instead, you just mark Properties and Associations with various multiplicities, 0..1, 1..1, 0..*, 1..*, and potentially by setting ‘unique’ to indicate Set semantics. However, there is no standard way to indicate containment by Map<K,V>. However, there is something related in UML, which is poorly understood and only rarely used, which is Association qualifiers. These can be used to represent a number of common things.
Containment by List<>
The most common container is just a List<T>. To represent this in UML in a way that can be reliably interpreted as a List, we assume that multiplicity + lack of the ‘unique’ constraint means a List, as shown in this model extract:
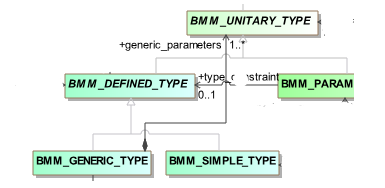
Here, BMM_GENERIC_TYPE.generic_parameters is intended to be of type List<BMM_UNITARY_TYPE>. The extractor generates this explicit type, as can be seen here.
Containment by Hash<> / Map<>
The following model extract is from the openEHR BMM model. The ancestors attribute is intended to be of type Hash<String, BMM_DEFINED_TYPE>.
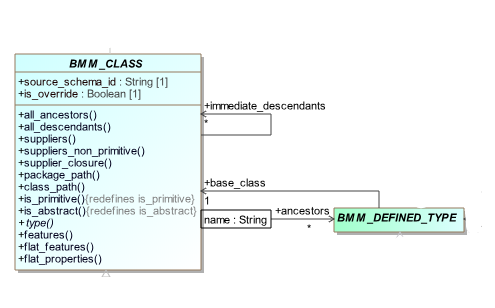
To represent a Hash table in UML, we use a trick: a named and typed UML qualifier (here, the white box labelled ‘name:String’) is added to the ancestors association, and the model extractor converts this to the intended Hash<> type, as can be seen in the extracted class definition. This is conceptually close to the idea of a UML qualifier, in that the type of the qualifier is used to refer to the target type; however, in our usage, the target type is used as well.
However, sometimes we really do want just a UML qualifier, i.e. a ‘key’ type. We employ a further trick to do that: if no name is used for the qualifier, the extractor interprets it as a List<QualType>, i.e. a list of just the key type.
We perform these conversions for openEHR code generation because we want to create specifications that precisely state what programmers should do. Having something like employees: String[0..*] is no use, if programmers are left wondering: do I do List<String>, Hash<String, Person>, or something else?
Needless to say, these are custom usages of UML, and are not standard in the industry, however, they are a necessary compensation for the lack of proper support for generic typing and containers in UML.
UML doesn’t do functional
Developers have been using functional languages and functional constructs for 40 years, but in the last 15 years, functionally-enabled languages are now the norm. Examples of mainstream languages that ‘do functional’ (more or less, – possibly ‘less’, as a Haskell programmer would say) are Scala, Java 8, and notably JavaScript and all its downstream languages. In functional programming, a Function or Procedure (where procedures are allowed) invocation is a first-order entity, often known as a ‘lambda’, after the Lambda calculus. Languages that do functional properly support function-currying, i.e. the ability to transform invocations by progressively filling in parameters, and controlling the moment at which the call is finally made. But even languages like Java 8 that don’t support curried functions, understand a function as an object.
Unfortunately, UML knows nothing about this. To get the effect of Functional programming (for example, to support argument types that are Functions), you first have to create your own meta-types, as we did here for openEHR.
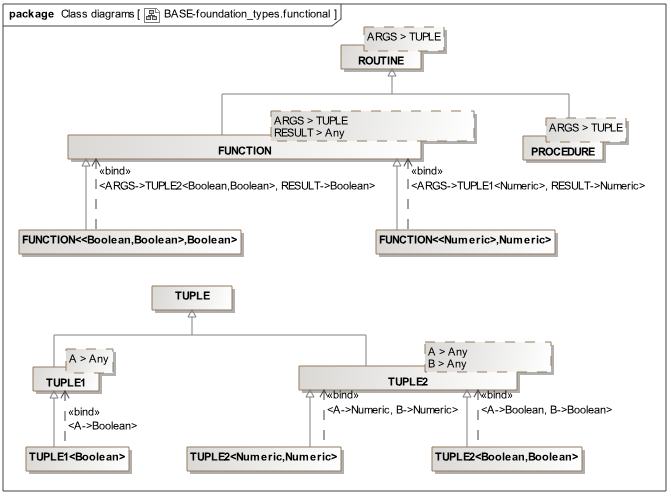
Needless to say, this is clunky and painful.
Conclusions
If you are still alive at this point, and have not gone and shot yourself, possibly after shooting others first, you will have some notion of what has gone wrong for UML. I would summarise it as follows:
- over-complicated;
- doesn’t support common programming needs such as generic types, precise container types, lambdas;
- doesn’t map well to modern programming languages;
- lacks a reliable serial interoperability format;
- not realistically usable for computing with models.
Why do we still use it? Well, people still need pictures of formal structures, and UML is just about good enough, coupled with our custom extractor, to generate our specifications. However, this is clearly not the long term future for us – we will do all our model-level computing with BMM, and possibly even think of generating diagrams from it one day.
The more interesting question is: where does UML go from here? I think unfortunately it will die, for three fundamental reasons:
- disappearing market – younger programmers using modern (functional-enabled) languages don’t use it;
- over-complexity – evolving from complexity to elegance is very hard for a managed standard, due to backward compatibility needs;
- lack of formal foundation – the lack of formal definitions and methods used to specify UML mean that its semantics can never be machine proved, and that formal methods, or even formal thinking can’t be routinely used with the UML meta-model.
Some people might say we no longer need diagramming languages, but many people like diagrams, and they convey a lot of information in a small space. Solving the diagramming needs of the future is likely to be done by a UML replacement, not a UML evolution.
There are two further, more general lessons to be learned from the UML experience. The first has consistently made itself known over my 30+ years in software engineering: you cannot build anything sophisticated that will last, without basing it on a solid, formal semantic core. Bad type systems, poorly thought out API ‘architectures’, models defined only in terms of pictures – these are all the hallmarks of failure in the making. UML needed to be based on a formal language – Z, B, Eiffel, anything solid would have worked.
The second general lesson is that ‘standardisation’ – even by engineer-led organisations such as the OMG, which are better than most standards organisations – is no guarantee of quality.


Really enjoyed this. I think that the “dissapearing market” point is the more depressing one not because UML would dissapear but because what it attempt(s|ed) to do would dissapear. It is now so easy to find a library that does XYZ that it is even easier for one to jump straight to code and even easier for them to come up with an alternative “library” with slightly different structure that fixes point ABC that will quickly become obsolete itself by someone else’s requirements. (I have specific examples).
The second most depressing point is having the notation for a formal language that does not exist (yet). This really resonated with me at least. In fact, UML could become something of a bigger deal than it is. There are certain things that don’t need an extra notation (such as Petri Nets for example: https://en.wikipedia.org/wiki/Petri_net) but could be very useful for analysis purposes (Workflow patterns for example: http://www.workflowpatterns.com/). So an established or familiar (by now) to developers description could become the bridge to more formal techniques.
When you are writing an algorithm for a journal, you cannot express it in a programming language. You have to express it in a more generic language (mathematical notation) via which you can also prove that it works (if required) or make other suitable inferences. In mathematical notation, you don’t really define a sequence (the equivalent of an `Array`). You specify a _`Set`_ whose elements are indexed by ANOTHER Set. So, your “Array” still contains UNIQUE elements (a_0, a_1, a_2, a_3) even if the values of the elements might be the same. Depending on what this OTHER Set looks like, your “Array” might end up being a mapping (effectively), a sequence or a “column/row oriented” array. But you almost never define these things at this level of granularity, because a Sequence is a sequence and everybody knows what it is, EXCEPT if you use some special sequences. UML takes a similar high granularity approach (if required). **BUT**, when you write an algorithm that is supposed to make use of Object Oriented concepts, you are on your own in terms of analysis. The closest I have found to an Object is a Group(https://en.wikipedia.org/wiki/Group_(mathematics)). THERE IS however, some developing notation (and formal framework) in the works of Luca Cardeli (https://en.wikipedia.org/wiki/Luca_Cardelli) (and others) and specifically the “Theory of Objects”(https://www.worldcat.org/title/theory-of-objects/oclc/853271036) (also here for an overview: http://lucacardelli.name/Talks/1997-06%20A%20Theory%20of%20Object%20(LICS).pdf) which, when you read been aware of UML make much more practical sense. This is why I am saying that UML could (can?) become something of a bigger deal than it is.
But these are very new concepts and to an extent very theoretical. A large part of the bibliography up to now seems to be concerned with type inference for example which might seem “too theoretical” for people who have “real” problems. And by real, I mean, they want to see buttons and sliders on the screen that do something as fast as possible….not what is deemed to be “theory”.
UML is indeed ambitious and it needs a PEP or RFC process that would enable you to submit initiatives such as BMM directly to its users and other “transactions” that would help trim the standard back to a realistic (but entirely practical) state.
There is another way to represent a Map in UML, it is by inheriting from Map-Entry-class, which represents one Entry (key/value) and then assign it to a property and using the list-trick with cardinality, that you described.
This way is advised in Eclipse-EMF (ecore). as said, the code-generators will then generate a Map. I am writing a model now using this, I will later see if it is the right. These things maybe change in versions of EMF.
Thank you for this thought provoking post on the challenges of UML: the complexity of the specifications, the horror of XMI across vendors and the undesirability of UML for describing computation. Personally I have used and still use UML to communicate ideas. Hopefully it will be revived from the almost ashes.