

Recent discussions on the FHIR chat forum with various HL7 people around the topic of how openEHR and other architectural frameworks (e.g. VA FHIM, CDISC) could work with FHIR led to a realisation that some people in HL7 at least don’t understand some of the technical basics of openEHR. This might simply because they have not been involved enough to learn them, but now that we appear to be in the era of FHIR, in which no e-health solution can be without FHIR (according to the now pervasive FHIR hype), I would argue that HL7 now needs to understand some of the basics of the other major architectural frameworks and model-based platforms in e-health – all of which precede FHIR.
One of the catalysts for this discussion was a recent post I made called Making FHIR work for Everybody, in which I proposed that FHIR could be opened up so that FHIR resources could be created that represent the reference models of other model-based architectures. This led to the above-mentioned discussions on chat.fhir.org (openehr channel), in which various misunderstandings about openEHR surfaced. I will now try to address some of these.
The first is the idea that only FHIR is implementation-oriented and that openEHR is somehow ‘theoretical’ and not implementation-oriented is not helpful. In reality they are both implementation oriented – both groups pursue their respective strategies in order to implement solutions that work; they just do it differently. One of the differences is at what point (what level of models) ‘implementers’ become directly involved. In FHIR, it is ‘always’ – FHIR is designed to be for and by application developers.
openEHR does take a different approach: separation of domain semantics from definition of the concrete means of communicating them, which necessarily means that how and when developers and clinicians are involved is different from the FHIR approach.
The other misunderstandings are to do with the types of artefacts openEHR has, and what kinds of people tend to build them.
* * * * * * *
So here is a short resume of the openEHR architectural basics, hopefully clear enough for people working with FHIR (and perhaps other approaches such as IHE profiling) to easily understand. I’ve added some highly scientific illustrations to help, in which I have indicated the kinds of people who work on each level of models:
- IT = software developer, formal modelling expert etc
- HI = health informatics expert
- HCP = healthcare professional
So let’s get started…
The foundational artefact of the openEHR approach is its Reference Model: a very stable information model that defines the logical structures of EHR and demographic data. It is not a physical data schema, but rather a formal, logical definition of the information held in any openEHR system. All EHR data in any openEHR system (yep – anywhere in the world) obey this reference model.

The next level of modelling is to create a library of data points / data groups that are independent of particular use – these are the archetypes. The archetypes are written in the Archetype Definition Language formalism. Generic terminology binding is done here.
We see creation of a library of use-independent data points as the only rational thing to do: there is no point modelling all the blood pressure data points, or any of the other 30,000+ clinical data points we expect to have, any more than once. Without a library approach, any clinical modelling effort is doomed to repeating definitions of what should be re-usable clinical entities. In openEHR, it is primarily clinical professionals and health informatics experts who write the archetypes – it’s their subject matter after all.
Implementation type people may also contribute, but it’s not on the basis of a particular system (unless the archetypes being developed are specifically for that solution); it’s to provide input on ‘what current systems do’.
The international library of openEHR archetypes (CKM) currently contains about 600 archetypes, or 9,000 data points. Other collections exist at the national and local level.
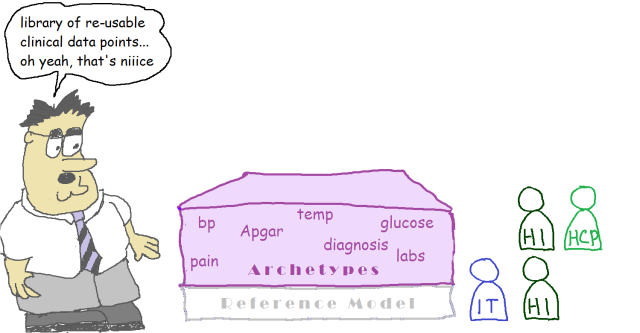
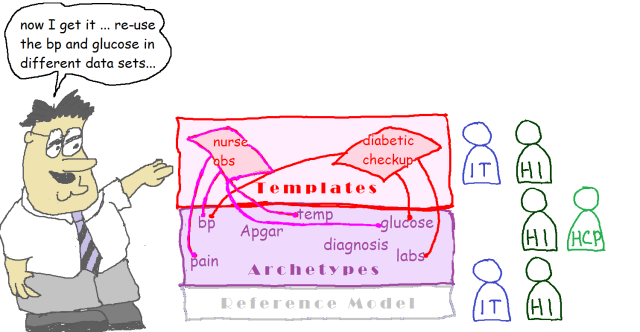
The next thing that is needed in any modelling ecosystem is a way of assembling domain data-points and data-groups into context-specific data sets – it could be the data for a form, a particular message, a document etc. In openEHR, this is called a Template, and this is what is deployed – all openEHR systems are built with templates, which in turn contain the relevant bits of various archetypes. A lot more terminology binding happens in templates, in order to designate the exact value sets to be used in the particular solution.
Templates are really a special kind of archetype, and they have an important property: they preserve the paths of archetype elements they use, even within variable depth structures. Templates are usually developed by implementers local to the solution being built, but you can also build a standard template for a country, e.g. a discharge summary.
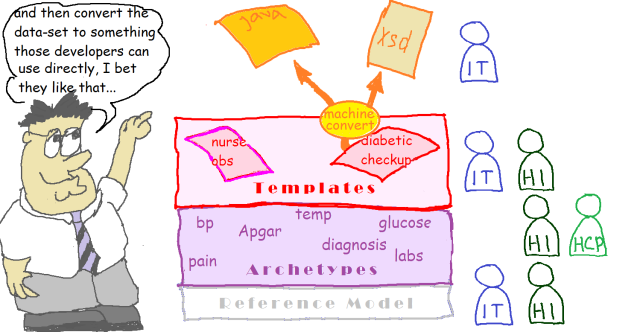
The next step is to create and persist data. Data in openEHR are defined by the templates, which means that they actually all correspond to the archetype structures and types. Doing this practically is where template-generated downstream artefacts come into play – we generate all kinds of things from the templates – XSDs, API facades, REST URIs, UI forms and so on. These are what are used by application developers.
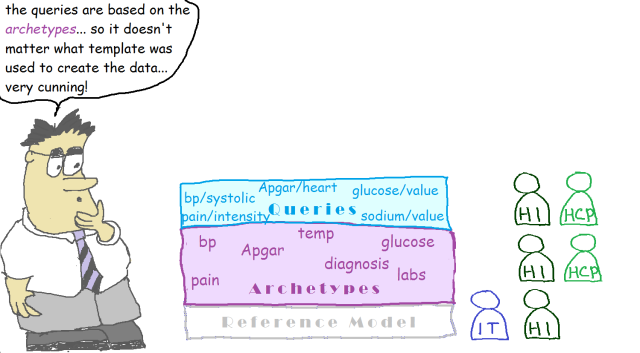
Now we get to querying: here we use a simple language (Archetype Query Language or AQL) based on archetype paths and terminology codes within a SQL-like statement structure. It includes the CONTAINS operator (like the ‘//’ XML operator) to enable location of paths in variable depth tree structures. This is all that is needed to enable queries written straight from archetypes to work over all that templated data. AQL querying is the backbone of operational openEHR systems – it sits behind most forms. The queries are all reusable, due to only being dependent on the archetypes.
What’s really happening in the above is that there are different points in the development of any given clinical model content at which different types of professional become involved, where it makes sense.
* * * * * * *
We don’t consider the model ‘stack’ above as an arbitrary or openEHR-specific design choice, we see it as reflecting some basic principles in information computing:
- Stable data: interoperable data require a stable Reference Model;
- Re-usable data elements: a library of re-usable clinical data points and data groups (archetypes) is required to represent the (very large number of) domain-level data elements that recur in all clinical data; this must be expressed independently of specific downstream syntaxes or formats;
- Data-set construction: a way of creating data sets from the data element library is needed (templates) to implement particular use cases (forms, messages, data creation scenarios);
- Implementation seamlessness: a way of converting data sets into usable software artefacts is needed to enable software development;
- Portable querying: a way of portable querying is needed that bases queries on the data element library rather than on physical DB schemas.
A summary of this thinking is provided in the (short!) Business Purpose of Archetypes section in the Archetype Technology Overview.
Now, as I always point out: openEHR is just a piece of an overall open platform for health computing. Full solutions need terminology, web APIs, applications, distribution services, security and so on. The openEHR White Paper explains openEHR in context.
Like any other standards effort (HL7 FHIR included), all of this is of course wrapped up in the sociological and political realities both internal to SDOs/SROs (standards-related orgs) and in the wider world. Other actors may try to impose their own ‘top-down’ visions or other ways of working which might not always fit nicely with the vision of the standards developers. Result: developing real practical social networks that have the desired outcomes can be a real challenge. As Dr Ian McNicoll (one of the CKM editors) always says, nearly all the real ‘problems’ are people-related, not technological. Nevertheless key aspects of HL7’s and openEHR’s (and all other ecosystems) internal visions do involve social aspects like crowd-sourced modelling and agile implementation, and these are quite tricky to get right.
I would make a plea for all major ecosystem/SDO/SRO groups to at least try to understand clearly the intentional design basis of the other ecosystems, and to distinguish that from unintended consequences due to sometimes inappropriate or misguided uses in the real world. When we do that, we can have better conversations about addressing mismatches among standards in e-Health.



Fantastic! You should edit an openEHR comic!
Brilliant – very easy read 🙂
Great job Tom.
Pingback: openEHR a Game Changer Comes of Age | Woodcote Consulting
Pingback: Ewan Davis: the content challenge – Digital Health Intelligence
Pingback: Weekly Australian Health IT Links – April 19, 2016 – Auto Article - Weekly Australian Health IT Links - April 19, 2016
Pingback: openEHR technical basics for HL7 and FHIR users | openEHR New Zealand