
We’ve made a lot of progress since my last post on this topic. We have published a 1.0.0 version of the openEHR Task Planning specification, which will go into implementation immediately in the City of Moscow e-health project. The current version will certainly be changed by that experience, but we believe is good enough for use in implementation, having been reviewed and worked on by our development team, including people from Marand (provider of the Moscow EHR platform implementation), DIPS (largest EMR vendor in Norway) and others from Tieto (Finland) and Moscow.
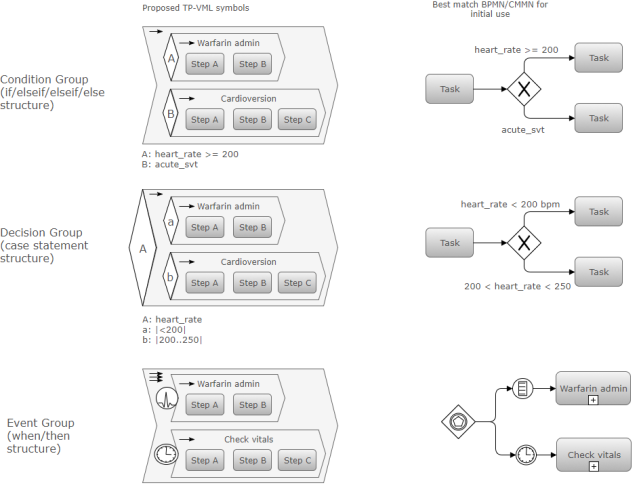
We are currently looking at creating a visual language for it, of which the above diagram contains initial ideas for the TP conditional structures on the left, with BPMN equivalents on the right.
One would be forgiven for wondering: isn’t this re-inventing the BPMN/CMMN wheel? We don’t think so. We’ve looked pretty carefully at BPMN (Business Process Modelling Notation) and its much newer cousin, CMMN (Case Management Modelling Notation), both OMG standards. CMMN is very new and while it has useful ideas, its formal model appears to be a very early committee attempt to describe a save format for UML tools that will have a CMMN mode added. It is not based on clear design concepts or a detailed theory of representing workflow, as far as I can determine. This may of course change.
Anyway, the current moment in time seems like a good one to reflect on the ways in which openEHR Task Planning is different from BPMN and CMMN, and even YAWL, a far more serious and formally solid attempt at representing adaptive workflow. The following table shows some of the key differences.
| Task Planning | BPMN / CMMN | |
|---|---|---|
| Conceptual approach | Task Plans are executable, and have a formal model of performers and allocation. | Non-executable; BPMN charts express business modelling needs; semantics not formally defined other than as diagram elements. |
| Type of subject (case) | Subject is an active and reactive agent (usually a human patient). | BPMN subject is a passive object, e.g. a package or a person in administrative workflow. |
| Graph | Implicitly defined by Task Groups, with the potential for rules like ‘exit group when at least N Tasks reach done state’. | Deterministic, defined by explicit links. |
| Processing model | Explicit distinction between processing executive and performers; every Task is done by a performer. Explicit model of allocation. | Performers are generally implicit; not clear who does a Task. |
| Hand-off (change of performer) | Explicitly represented by a Hand-off Task. | Implicitly represented as a signal across lanes. |
| Task lifecycle | Task is computable with a formal lifecycle defined by a state machine; there is a formal definition of when a Task becomes ‘available’ to perform. | No explicit Task lifecycle. |
| Performer relationship | Task is performed by performer; performer may override conditions preventing a Task from becoming ‘available’. | Unclear. |
| Context management | Context is a formal concept; context switch and fork are represented; callbacks are formally modelled. | Context switching is informally represented as jumps across lanes. |
| Context data | Subject and environment state variable definitions and how populated is explicitly modelled. | State variables can be stated, but not how they are populated. |
| Training level | Granularity of Tasks can be dynamically controlled on the basis of performer experience. | N/A |
| Clinical concepts – Order sets | Order sets with delivery schedule can be represented as openEHR Instructions + Task Plan. | N/A |
The Task lifecycle state machine is shown below.
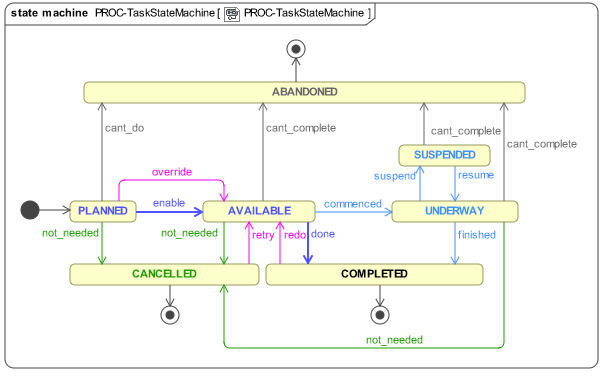
There are many things that are superficially common to both TP and BPMN/CMMN, i.e. the basic notion of Task. But as soon as one looks carefully at what a Task is in BPMN, we see that it is not semantically defined, other than as a modelling notation element. The overarching difference between openEHR TP and BPMN/CMMN is that the former is intended to be directly interpretable by an execution engine, which can communicate with applications, allocate performers, accept signals indicating new state information and manage context switching, forking and callbacks.
This is far closer to the YAWL mindset, and in fact, YAWL has provided us with many useful lessons. It is a far superior technology than BPMN or CMMN, and it’s a pity it is not used more widely in industry. Nevertheless, even YAWL’s meta-model is wanting in areas of adaptiveness and declarative / non-deterministic workflow representation, a fact recognised by Wil van der Aalst, one of the primary authors, in his later work.
The idea of creating a new visual language initially seemed somewhat crazy, but there are reasons to proceed:
- BPMN and CMMN visual language is not particularly intuitive (there are numerous strange symbols for variant kinds of events, gateways, signals etc).
- It’s reasonably easy these days to build a new diagramming mode for tools like draw.io, and even Camunda.
- We could try to re-use parts of BPMN and CMMN, but there is the danger of making model builders think they are getting BPMN semantics, which will not be the case.
We are still on a journey of course, and the next few months will tell us if we are on the right track. If we are, we will start to look seriously about representing full Care pathways of the sort published by NICE and other major health agencies, and then how to computably relate Task Plans for real patients and Care Pathways, which are for model patients.
We will certainly obtain much evidence from the Moscow project, as well as from Norway, where DIPS has long-term familiarity with clinical workflows, the Intermountain Healtcare ABD project, and other locations. Our models feel good from my point of view, but there’s nothing like a real implementation to knock the wind out of the best of models.
Let’s see how we go.


Petri Nets with a process/procedural accounting system are very much solutions I have found viable in comparison to BPMN. (https://github.com/yawlfoundation/yawl/releases) the reason it helps is to make clinical workflows integrated into processes. (https://www.clinicalworkflowcenter.com/resources/patterns-and-petri-nets)
I’ve actually used the YAWL tools in our research – they are a bit clunky, but the underlying paradigm is much more solid than BPMN. They don’t appear to have great industry support, unfortunately, and also dealing with non-deterministic workflows is still hard, even if easier than with BPMN. We’re not using a Petri-net implementation as yet. Our current approach is tracking lifecycle states in Tasks, which I think may be equivalent. Thanks for the CPN references.