
One of the basic elements of design common to all workflow languages, including YAWL and BPMN, is the inclusion of logical expressions on decision nodes. This seems harmless, and we followed it in openEHR’s Task Planning specifications. However, it is clear that this is a basic error, and that any workflow containing such expressions is unmaintainable and semantically unreliable.
EDIT: it was pointed out by Grahame Grieve that the initial version of this post did not distinguish adequately between ‘expressions’ and ‘decision logic’. So to be clearer: expressions are just one (common) way of expressing decision logic – the expressions on outgoing paths of a decision node in a BPMN workflow together constitute parts of a decision algorithm that could be rewritten as a case of if/then statement. However, there are of course other kinds of decision logic – ranging from lookup tables to AI. I’m just dealing with the algorithmic and lookup table kind here (lookup tables are just a degenerate kind of algorithm).
EDIT2: I treat the mention of any non-primitive formal element, including function calls and operator expressions as ‘expressions’. This may not have been initially clear.
Consider a decision node with outgoing edges with expressions like the following:
systolic_pressure >= 180 mmHg OR diastolic_pressure >= 110systolic_pressure >= 160 mmHg OR diastolic_pressure >= 100systolic_pressure in {|140..159|} mmHg OR diastolic_pressure in {|90..99|}
Visually:

We have to ask what these expressions actually mean. What does systolic_pressure >= 180 mmHg OR diastolic_pressure >= 110 represent? Where did the 180 and the 110 come from? Why the ‘or’ operator? This particular expression is a common formula for ‘hypertensive emergency’, but there’s no reason it couldn’t be different. New research might change the numbers, or the logical operators, or the expression entirely.
In fact, what we really want to do on the outgoing branches of such a decision node is to use classifiers (ideally coded) like:
- hypertensive emergency
- hypertension stage 2
- hypertension stage 1
Associated with the decision node itself is the variable or rule whose result is one of the above classifiers. Visually:

The expressions that equate to the classifiers might change over time, but if we design the workflow using semantic classifiers rather than the expressions that currently generate them, it will be semantically reliable (at least insofar as the classifiers themselves are agreed upon in that area of medicine), and immune to changes in those expressions.
At a more basic level, no literal values should ever appear in decision nodes in a workflow either – even if expressions were allowed. Imagine two expressions containing the fragment heart_rate > 180, in different places in a workflow. Is it the same 180? If one needs to be changed, does the other? Perhaps one of them relates to ordinary tachycardia during childbirth, and the other is to do with atrial fibrillation. They could easily be different values.
A common form of variable + classifiers decision pattern is boolean-variable + True/False or yes/no classifiers.
Formally, the only two kinds of decision gateways we should therefore allow (we’ll get onto decisions tasks and DMN in a minute) are typed as follows:

And for the Boolean form:

In the above, ‘CodedTerm’ is a type representing coded term from a terminology. (The Boolean form can easily be considered a special case of the coded form, where the only terms allowed are ‘yes’ and ‘no’, and the rule is always stated as a proposition such as ‘is_diabetic’.)
Decision nodes in workflows can only be safe if they are built in one of these two ways. To be fair, that is the case in many workflows anyway, but it is not generally through conscious discipline, but (most likely) long-term experience with simple flow charts. To build an executable workflow (without using DMN), one has to write logical conditions into the workflow, as implied by this help page from Camunda.
What is most important about the above structures from a formal point of view is that the decision node itself is associated with a ‘context variable’ connected to the ‘case’, i.e. the subject (normally, the patient), rather than just being some ad hoc question. This doesn’t mean the variable has to physically relate to the patient (as blood pressure does), it might be a variable such as ‘ICU bed available?’, which relates to the handling of the subject.
The real question is: where do all those logic expressions go if not in the workflow? If you are using OMG’s BPMN, then DMN, the Decision Model Notation is one answer. In this approach, you treat making a decision as a task, and its output drives a following decision node. We can see how this works from the following figure, taken from the DMN standard (fig 5, p23).

In the above, the BPMN workflow is on the left. The ‘decide routing’ decision is fully modelled by the decision model on the right, which incorporates a decision table, visible at the bottom.
There are various parts of the decision model which can include annotations, business knowledge model (essentially, the decision algorithm or table), data inputs, knowledge authority and a few other details. Computationally what matters is the input and output data variables and the decision algorithm, which may be a table, but could also be an expression written in FEEL, the expression language defined in the DMN standard.
A new OMG standard, Shared Data Model and Notation (SDMN) that is nearing completion is used to specify the data elements.
This approach is better than having the decision logic inline, salted throughout the workflow model. Whether it is really sufficient is another question, since having each decision in a separate ‘model’ isn’t quite how clinical pathways are defined. Instead, all the input and output variables, rules, documentation, overall reasoning, caveats, attributions and references are normally in a single guideline document, or in one of a linked set of documents. Another OMG standard, BKPMN, along with SDMN, is intended to provide such packaging. (These standards are part of a group of standards known as ‘BPM+’; website here).
Here are two examples of real guidelines in medicine.
- RCHOPS-21 chemotherapy guideline, by NHS Thames Valley Cancer Network;
- Intermountain Healthcare Acute Stroke guideline.
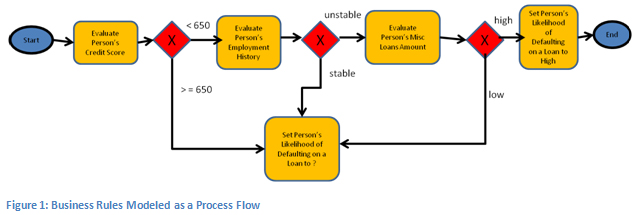
Just for fun, here is what just one decision node looks like in the latter guideline:

It’s not too hard to see that to properly represent the above is likely to be a challenge for simple rule algorithms or tables.
Regardless of the exact details of BPMN / DMN / SDMN / BKPMN, it is very clear that workflow and decision logic need to be completely separated, so that decision logic can be managed as its own knowledge artefact. We do this in openEHR using Task Planning (the BPMN equivalent) and Decision Language (the DMN equivalent) – the general approach is the same. See here for some examples.
The challenge for representing real world clinical guidelines computationally is going to be finding concrete representation that achieves not just separation of concerns, but coherent, governable artefacts that can be authored and maintained by domain experts – the same kind of thing we have achieved with openEHR archetypes, but for process models. I believe that there is still some way to go on this, but both the emerging standards and various operational representations (of which openEHR is just one) are homing in on a real solution for the future.
One consequence in principle of taking this separation seriously is that if the BPMN meta-model were defined today, it could have much simpler decision nodes – only the two (really one) pattern described above would be allowed – expressions would be banned (the event types would remain though). This is unlikely to happen, for reasons of backwards compatibility, so the best we can do is teach people to treat inline decision expressions in BPMN models like goto statements in programming languages that still have them: avoid like the plague.
For those who live and breathe workflow, none of the above is new thinking of course. Here’s a nice (and more detailed) article (2009) by Barbara von Halle and Larry Goldberg of Knowledge Partners International on why decisions should be separated from process definition.


A lot of the problems that openEHR deals with are “universal”. It would be worth making this kind of considerations in other domains as well.
In no particular order:
1. Indeed, there is no distinction between the “expression” and “lookup table” viewpoints of functions. It is the difference between the intensional and extensional representations. In fact, you can do away with expressions by having a language that does not have operators. This however is not very user friendly, as it turns this 3*(5+2) to this mul(3,add(5,2)). In this way everything is a function in the (current) context of the EHR and you don’t have to worry too much with an expression not being as “flexible” as a function.
1.a In either of the above cases however you also have a bigger problem. Rarely are functions just the matter of their operands. They also take parameters. So, now the problem that you have is how to represent / store / modify these parameters. It is another version of what is presented in this article as “why 180”? Or in other words, “gt(x, 180)”. Whether gt is interpreted as “greater than” or some other function, you still have to supply the 180 as a parameter. Which, to my eyes at least would be a huge headache if the conditional on following a branch was the result of an….”AI” type of function.
2. The article is making a point with a very particular focus. I may lack experience of the viewpoints taken by the models (or more generally), but an additional consideration is “Who takes the decision”? If we think about who takes the decision, no hard thresholds / parameters would need to be stored. When you arrive at a decision point supply all necessary information required to take the decision but do not take the decision. Which is what the “Acute stroke” workflow seems to suggest. The function of is_symptomatic is not defined. It is “implied”. So, semantically, what is attempted to be modelled? The “if you make x call at this point, this is what you should do next”? Or the “this is how you make the call”?
We’re crossing a few issues here. Firstly, when I say ‘expression’ I mean anything beyond an atom – i.e. function calls, operator expressions and so on. Operator calls can all be reduced to functional form (as per the openEHR EL spec – https://specifications.openehr.org/releases/LANG/latest/EL.html, which just follows standard practice in this area). Secondly, the nature of ‘real’ decisions is a much deeper discussion, and you are right that they are far more slippery in real life than might be implied by models containing well-decision gates with well defined expressions (essentially case-statements). In openEHR we included the possibility of two other kinds of decision nodes: completely ad hoc (no established formal criteria) and defined, but overridable by user at execution time.
>> we included the possibility of two other kinds of decision nodes: completely ad hoc (no established formal criteria) and defined, but overridable by user at execution time
I am very glad to hear that, it sounds really interesting.
Re: functional form, I understand.