
Why don’t we have widespread clinical decision support (CDS), computable guidelines, clinical workflow (plans), and why don’t the pieces we do have talk to the health record? The first time I heard such challenges framed was around 2000, and even at that moment there were experts who had been working on modern versions of the problem for at least a decade, not to mention earlier generations of ‘classical’ AI systems such as MYCIN. So it’s not for lack of time.
After 20 years of staying out of this particular kitchen, I took the plunge in 2015, with a number of projects including Activity-Based Design at Intermountain Healthcare, a major openEHR development project called Task Planning (partly funded by Better.care in central Europe and DIPS in Norway), as well as some minor involvement in recent OMG BPM+ activities. We already had within the openEHR community the Guideline Definition Language (GDL), a fully operational decision support capability originally developed by Rong Chen at Cambio in Sweden (resources site). This provided us with a lot of useful prior experience for building a next generation combined plan/guideline facility.
Here I will talk about what I think has been conceptually missing for so long.
The challenges
Let’s start with the oldest problem, around since the advent of Arden Syntax (now an HL7 standard; interesting paper from 2012), the original (some would say the best) serious modern attempt at computable guidelines. This is the ‘curly braces problem’ otherwise known as how to make the decision support layer talk to the EHR. This is a reference to the braces used in Arden to refer to external data entities, generally understood to be from the EHR. The problem historically is that all EHRs (i.e. EMR products) are different and generally don’t expose anything like a standard interface. Clearly, if this problem is not solved, the entire endeavour will remain stillborn.
However, this isn’t the only reason we’ve been paralysed. Coming from the direction of guidelines and care pathways, as published in PDF or HTML form, the limitation has been the lack of a sufficiently sophisticated formalism. If we consider a real guideline, e.g. this Intermountain one for managing Acute ischaemic stroke, none of the available formalisms has been demonstrated to get close to representing this. Now, there is no lack of formalisms, including Arden, ProForma (original paper by John Fox), and Asbru to name a few (see openClinical for a list). And no lack of brains behind them, to put it mildly. And yet, we remain far from routine use of computable guidelines in modern healthcare.
Meanwhile the need has never been greater. The complexity of care in a modern team-based environment, and with highly detailed evidence-based care pathways developed is literally too great for even the keenest Harvard-educated or Oxford-educated MD’s mind – the 7±2 problem bites. Clinical professionals need help!
A third challenge is usability. Clinicians want to work with the patient, either in the GP / specialist setting, or with an in-patient, not stare at a computer screen. A guideline in the former situation might be to diagnose angina from various symptoms and investigations. The above-mentioned stroke management guideline would be used in a hospital. In an out-patient / day-clinic setting, a common type of guideline is chemotherapy dosing and administration (e.g. RCHOPS-14, 21 etc).
The challenge here is: how to integrate the guideline into the workflow of the clinician? At the moment, published guidelines are printed on paper and even left in folders in wards, or they may be on screens. But just have a look at any non-trivial guideline. No doctor or nurse has the time to read 20 pages of dense technical medicine while actually seeing the patient. Now, there is usually already an EMR, so the technical question is: how to integrate the guideline into the existing applications?
A fourth challenge is one of clinical semantics: how to adapt guidelines for particular conditions to a real patient who usually has other conditions, is already taking other medications, and may well have a personal medical history (e.g. previous heart attack, thrombosis, etc) that precludes some of the elements of the guideline now being considered. Guidelines can’t just be ‘used’, they have to be adapted carefully to the patient phenotype, medical history and current situation.
The difficulty for achieving widespread, sophisticated use of decision support is that all of the above need to be solved to make anything work in an acceptable fashion. It’s a huge challenge.
Some lightbulb moments
The seeming impossibility of solving the above is partly what keep me away from the whole area, but having jumped in a few years ago, there was no getting away from them.
The first useful conceptual idea I got from Alan James, the head architect of the Intermountain ABD project (sadly we lost him in 2018 – here he is doing his favourite thing with me and David Edwards, ABD project lead). One day at lunch in the Salt Lake City office he was going on about something deep (Alan didn’t do superficial), prior to me having had coffee. I stopped him immediately, telling him he wasn’t allowed to speak until I had obtained caffeine, and this was clearly a 2-shot conversation. With coffee in hand, we talked our way around various interesting things, during which he let drop a seemingly innocuous statement well I think docs really do a bit, decide a bit and record a bit [in the EHR]; decision support isn’t some separate thing, it’s happening all the time. The ABD sponsor, Brent James, long term head of the clinical quality programme at Intermountain, and a world expert on clinical guidelines confirmed this.
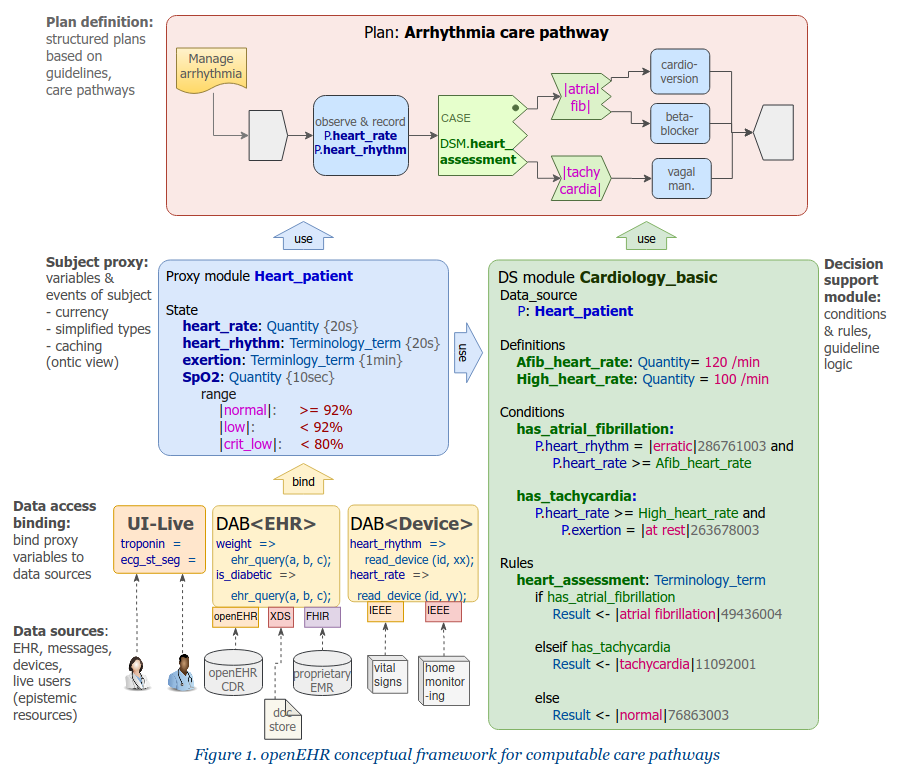
This stuck in my mind, and now I see it as a key lesson: the cognitive activities of the clinical are such that ‘doing’, ‘deciding’ and ‘recording’ are all mixed up, and any viable solution has to support this, and preferably make it invisible. What this tells us is that plans (the ‘doing’ part) and rules (the ‘deciding’ part) must be mixable at the finest granularity and yet remain separated, since they are categorically distinct artefacts. We thus have at least two formalisms, one for plans, one for rules, but they must talk to each other at the finest level.
Speaking of making things invisible, David Edwards, the ABD project lead and a great colleague and friend, showed at least part of the way to solving the problem: using voice. In the face of some scepticism from me and Alan, David not only made voice controlled screen workflow work, he changed my and Alan’s minds about its central importance. A voice-enabled application workflow not only keeps the sterile field intact (wiping out one of the main obstructions to safe use of physical IT interfaces, i.e. screens, keyboards etc) but is more efficient than those other methods when done properly (e.g. using model-based applications driven by clinical data models and constrained terminology value-sets). The Intermountain ABD system is designed such that no-one has to touch anything, and all the EHR recording is done by the time the voice/screen interaction for the clinical work is over. No ‘noting’ to make you late for meeting friends for dinner.
A further lightbulb moment has been the realisation that the curly braces problem – the question of EHR integration – is not mainly a question of interoperability, i.e. defining some uber-vMR standard for talking to all EHRs. Instead it is primarily a question of conversion of epistemic data (data from EHRs, devices, users) to ontic entities that reflect reality, hiding the details of data sources. This entails a ‘lifting’ and transformation of data to populate a set of reality-based facts about the subject. The real question is thus of appropriate semantic transformation to do things like convert possible recordings of e.g. diagnosis of diabetes into a Boolean variable is_diabetic, which truly reflects the subject’s diabetic status, and also makes direct sense to a guideline author. This might require the doc or patient to be asked in the absence of other information.
A promising conceptual architecture
The hard parts remain: finding sufficiently sophisticated formalisms for plans and rules, and understanding what an ontic variable is, in order to solve the EHR integration problem.
The first is a question of creating baseline formalisms for the right things, and organically evolving them. In openEHR, we created the Task Planning (TP) specification for the plan part, and are working on a Decision Support Language (DSL), an evolution of GDL. The key architectural innovations we have adopted are these:
- complete separation of rules and expressions from plans: plans can only mention expressions, not define them;
- rules and expressions are written using ontic variables, i.e. variables such as
is_diabetic,has_pre_eclampsia,oxygen_sat,neutrophils, which are at the cognitive level of the working clinician, not at the data level of the EHR.
The first point is important. Simple conditions like systolic_bp > 140 mm[Hg] while seemingly innocuous to a programmer are always significant clinically, and have usually been devised by a professional college or other peak body to represent a diagnostic or other criterion used in diagnosing or treating patients. Such conditions need to be collected in decision support rules artefacts and documented, authored and governed appropriately, not buried (possibly in multiple copies) within plan structures.
To enable both plans and rules to be written in a natural way, we need a third artefact, which we now call the subject proxy. This contains a definition of the ontic variables, and acts as a smart representation of the subject (i.e. patient):
- it acts as a data concentrator for various kinds of source systems via data access bindings;
- it will get data from users if necessary;
- it performs type and name conversions;
- it can track historical values over time;
- it can be used to represent reference ranges, and generate events.
A subject proxy object (SPO) is needed for each guideline or set of guidelines, and related plans. Each SPO has a relatively small number of specific variables relevant to just those guidelines and plans. Behind every SPO is a data access binding that obtains data from source systems of all kinds, and takes care of the ‘mess’ of data integration. This mess is unavoidable, but the mistake of the past has been not to separate it out from the plan and CDS level artefacts that use it. The Subject proxy is thus a conceptual solution to the curly braces problem.
An example of the three kinds of artefacts (Plan, Subject proxy and Rules) is this RCHOPS-21 chemotherapy guideline.
The small size of each SPO vastly reduces the difficulty of interfacing to the EHR. Many guidelines operate off 5 or fewer variables. Associated plans typically need more, but the total for a sophisticated guideline could easily be 20. The RCHOPS-21 guideline runs off 6 core variables, with probably another 15 needed to cover all pre-assessment and concurrent medications.
This approach means that the curly braces problem is no longer a question of finding a vMR (virtual medical record) interoperability standard for all possible data and all possible EMRs, but a quite different problem of how to define and engineer ‘thin’ interfaces to general sources of data, specific to particular clinical specialties.
Where now?
The resulting separation of concerns is thus into four kinds of entity, as shown on the diagram at the top of the post. In openEHR, we aim to evolve Task Planning and GDL2 to an integrated form that instantiates this architecture. An important part of the puzzle is a formalism for expressions and a meta-model for representation of computable rules. In openEHR, we have built this using the Expression Language, based on the extended Basic Meta-Model (BMM). This separation of concerns will make it easy to use industry-standard facilities such as CDS-hooks (already in use in GDL).
Another major effort underway in this space is in the BPM+ community, based on the OMG’s BPMN (workflow model), CMN (case model), and DMN (decision model) standards. This group is working on evolving and integrating these standards with some newer ones (e.g. ‘situational data’) for use in healthcare. I believe they will come to the same conclusion as we have with respect to the conceptual architecture.
HL7 also has a standard called Clinical Quality Language (CQL) which is as far as I know being used in the CDS domain.
(Interestingly, both of these latter efforts have had to solve the expression language problem as well, and have built-in formalisms to do this.)
It may be that the nomenclature I have used will not be the final one used in industry, but I have some hope that we are getting close to a standard view of the correct separation of concerns, what the artefact types are, and how to represent them. This will allow us to get on with the business of evolving their semantic power without perennially being trapped in the side-alleys of technical details.
There are many details I have glossed over here, but they appear a lot more soluble with this new conceptual architecture. The RCHOPS example mentioned above shows that we are at least partway to being able to represent non-trivial guidelines in all their detail: we had no trouble representing it in the Task Planning, Decision Support Language and Subject Proxy representations as they currently stand.
Lesson: always separate your concerns.


Hello Thomas,
I follow all your interesting articles, as I am particularly interested in the representation of clinical guidelines and now in the integration of CG knowledge in clinical workflows. In my opinion you are right in using ontic variables, as this is close to natural language and in fact this is what reasoners use in ontologies, although I have always wondered why ontology editors and reasoners need to explicitly move EHR data (subjects) to ontologies as individuals, in order to be able to reason, instead of somehow accessing a virtual “individual” data dyamically from an EHR.
If I understand well what you mean by the proxy subject, this is similar to what Drools does with the POJO classes, which are a dynamic representation of a specific clinical fact (subject).
I found particularly interesting your comments about a DSL as an evolution of GDL, and the separation of concerns between the workflow and the knowledge rules. This is key also for maintaining knowledge by the clinical expert.
Anyway, I had a couple of questions for you, regarding OpenEHR TP. Is there any modelling tool supporting TP-VML and its translation into JSON or XML?. Regarding the use of time in OpenEHR TP, are all Allen operators supported? And where can I find an overview of the usage of OpenEHR in clinical insttutions?
Thanks in advance, always a pleasure to read your articles.
Hi Natalia,
good questions. You can see some more recent examples here: https://specifications.openehr.org/releases/PROC/latest/tp_examples.html#_multi_drug_chemotherapy
In particular the syntax (and its meta-model) are evolving. We are specifying that in the Decision Language spec – see https://specifications.openehr.org/releases/PROC/latest/decision_language.html
Currently, there is partial support for TP modelling in the Better ArchetypeDesigner tool (https://tools.openehr.org/designer/#/) which has a graphical mode for doing TP structures. However, it doesn’t do the decision logic part yet – we are still working out details in the specification.
Regarding Allen operators (temporal operators), I probably need to do a bit more work on them, but we rely primarily on such operators (or most of them) being defined in the formal foundation classes (https://specifications.openehr.org/releases/BASE/latest/foundation_types.html#_interval). You can see functions like intersects() etc; we would need to add to these to represent things like A ends before B or the other way round. To make them temporal, we need to specialise these functions on types like Interval etc (https://specifications.openehr.org/releases/BASE/latest/foundation_types.html#_derived_interval_time_types), and then decide if we want to add syntax aliases like ‘starts-before’, etc. I don’t see any difficulty in doing the formal part, but I am not yet sure of the best syntax operator approach – every possible combination of ‘starts-before’, ‘starts-after’, ‘ends-during’, ‘overlaps’, etc or something else.
Where TP is in use: it is still in development but being trialled in the Moscow EMIAC EHR system, and some implementation at DIPS in Norway. Where openEHR in general is running (this is probably about 1/3 of deployments): https://www.openehr.org/openehr_in_use/deployed_solutions/
Thanks a lot. I have taken a look to all links you mentioned. I have seen in the openEHR examples that you mention that TP-VML libraries can be downloaded into draw.io but when you click on them, an http error is returned. For example when you clink on https://specifications.openehr.org/releases/PROC/latest/tp_vml/draw.io-lib/TP_VML_plans.xml
Further I have seen that there is a mdzip file for Magic Draw which includes PROC classes. Would this work for drawing TP-VML flows?
The Better desginer at https://tools.openehr.org/designer does not work, when you create a new WorkPlan archetype it does not do anything. Is this some kind of known error? I have tried with edge and chrome just to be sure.
Thanks again for your feedback. Have a nice day.
Natalia
Thanks a lot. I am trying to download the draw.io libraries for TP-VML but the links do not work properly, I get an HTTP error. Also the Better Archetype designer tool includes links to create a work and a task plan, but they do not work either.
Do you know where the TP-VML icons can be dowloaded?
Thanks in advance.
Greetings
Natalia
Hi Natalia, the links are at https://specifications.openehr.org/releases/PROC/latest/tp_vml.html#_draw_io_tool_mode
I just tested them, they work fine for me. Which HTTP error are you getting?
You can also find via the Github repo directly at https://github.com/openEHR/specifications-PROC/tree/master/docs/tp_vml/draw.io-lib
Let me know if this helps.
Hello Thomas,
Yes, I could download now the libraries from the specifications website. Thank you so much. When I tried, I got an HTTP 404 error, Not found. Maybe it was some temporal problem of the website.
Thanks again, have a nice day!
Hello Thomas
Regarding the TP specification, if you need to model two parallel tasks, one is a daily medication and the other some lab tests, and you want to interrupt the medication when the lab tests are ready, would a repeatable task be ok to represent the medication with a termination condition (either a system or manual notification from the lab)? is there any other (better) way to represent that?
I have seen that task-waits delay the start of the task, but in this case I want that a task in branch B interrupts a task in branch A.
Thanks in advance
Natalia
Hi Natalia, I suggest it would be better to post these kinds of detailed questions on the openEHR Discourse category dedicated to these specifications (create a new topic) – https://discourse.openehr.org/c/specifications/task-planning-gdl/27
Then more people will see and discuss it.
Thanks
Hi,
Great article. Regarding this line: “If we consider a real guideline, e.g. this Intermountain one for managing Acute ischaemic stroke none of the available formalisms has been demonstrated to get close to representing this.”–> I think we’re close, but not through formalisms. The problem we encountered with increasing complexity of guideline wasn’t whether we could get there with code, it was avoiding errors once we had arrived there. Medicine was just too complex. Our ‘lightbulb’ was to go back to computer science history and see how a similar problem was solved with WYSIWYG (what you see is what you get) design. That representing in any other way was not only harder, but less safe. Happy to show you
I would be very interested in that. If you have links, please share, or feel free to contact me – http://www.arssemantica.com/