

One of the many things the FHIR silver bullet hype claims FHIR will solve is the EHR, along with Clinical Decision Support (CDS), Care Pathways, and who knows, paving driveways and launching spacecraft. I have made various arguments against silver bullet psychology, which I will not repeat here, but do want to look (again) at the FHIR v EHR question (a previous post on FHIR v openEHR looked at some aspects, and a second at further technical details).
As usual, my motivation is to help professionals and particularly publicly funded organisations in the e-health sector understand the details (where the devil lives…) so that they may determine which standards are useful for which problems, and conversely, which are not. The bottom line is: a specification being a published de jure standard is no guarantee of quality or fitness for purpose, and indeed the committee-based nature of standards production is often a severe hindrance to quality. The best approach when considering using published standards for complex multi-year endeavours is: assume nothing, investigate everything.
Why ‘FHIR versus the EHR’? Firstly, the question comes up because there are people and organisations that have been convinced that they can build an EHR system from FHIR. Since I hate to see organisations in the healthcare domain lose money and time that could be spent on actual progress, I want to explain why – technically – this has almost no hope of working. This is also an opportunity to further discuss issues with FHIR as it is now (DSTU4) and what can be done to address them, and make it work well for the use cases for which it was designed. See previous posts on inconsistency, lack of modelling and the formalism for reference.
NB: in this post I am using the term ‘EHR’ in the sense of the key back-end platform components Clinical Data Repository (CDR), Demographics etc, not a whole-of-product EMR sense.
Content
First things first. What is an EHR? In the abstract, we can think of it as a memory device for recording what goes on during healthcare processes. Roughly, what can be recorded includes the following kinds of primary information:
- requests for care
- administrative items
- observations, including patient-provided information
- clinical decisions, opinions
- plans
- orders
- actions (that have been performed)
- consents
- financial items
At any particular case, the primary information usually consists of a number of related data elements in a structure.
Context
Context data get committed over time, as the care process – say an episode of care at a hospital – unfolds. However, there is never just one ‘process’: care takes place within an episode of illness or other health concerns, and there may be research or clinical trials going on as well (the ISO 13940 Continuity of Care standard may be referred to for a details description of such things). At the moment in time when the primary elements are captured, there are various kinds of context that may be extant. These include:
- situational (encounter) – the real world situation being captured:
- subject – who is the information about?
- provider – who provided the information?
- other participants – other actors who were part of the situation
- where – location, e.g. physical, organisational
- when – timing information
- how – methods, instuments used to generate / obtain information
- protocol
- guideline(s) operating that determine care steps and/or decisions
- order workflow
- identifiers of requests, responses
- episode of care
- start (admission), end (discharge, death)
- institution
- care pathway
- structured pathway governing guidelines, order sets to be used
- care plan
- which individualised care plan (if any) is governing the current care; may refer to care pathways, order sets, guidelines etc
- episode of illness or other health concern (e.g. pregnancy)
- date(s)
- medical research, clinical trials, public health investigations etc.
How these are recorded depends greatly on what is going on. Situational context is often recorded along with with the primary data structure, if it is a single sample, e.g. a single blood pressure or diagnosis. But 24 hours worth of vital signs (BP, heartrate, SpO2) from a bedside monitor will consist of some thousands of samples, and they would typically be recorded in a more efficient data structure, with the invariant elements being recorded only once.
The details of longer running contexts, such as episode of care, episode of illness, care pathway, care plan, and any others, are typically not recorded for every item that occurs during that context, but in other ways, e.g. tagging, folders, or by being inferred from querying (e.g. an episode of care could be determined by looking backward for an admission and forward for discharge event).
The Design of an EHR (CDR)
In general, the design of an EHR system CDR is built around the act of writing chunks of data that document real world events – often termed clinical statements – as they happen. They fall like constant rain into the CDR, which we can think of as being like river flowing through time. Each committed item is inserted to a logical ‘context container’, and is sometimes carrying some of its own context data. Everything will also be versioned and audit-stamped, in order to support medico-legal and privacy requirements, e.g. GDPR and HIPAA. The utility and usability of the EHR as a record of healthcare of the patient, is built from the history of versioned data commits over time – this is what defines the semantics of the patient record.
At a semantic level, the design of EHR information models to support structuring over time, managed lists (problems, medications etc), linking of events, threading of problems etc is completely oriented to how the healthcare processes in the real world look as they occur.
At a technical level, information models and databases are normally designed to minimise redundancy, so as to avoid inconsistency, not to mention greatly reduced data volume (contrary to amateur opinion, data volume matters a great deal in a real enterprise computing context: try getting a quote for 50TB of RAID 10 storage instead of 5TB from any cloud infrastructure vendor). This is a basic computing and DB design principle, and supports the standard model of ACID transactions in a persistent system. The practical consequence of this is that a well-designed EHR information system records any particular thing – whether it be content or context – only once.
We can visualise how data look going into an EHR over time as chunks of modelled, structured data, interspersed with context.
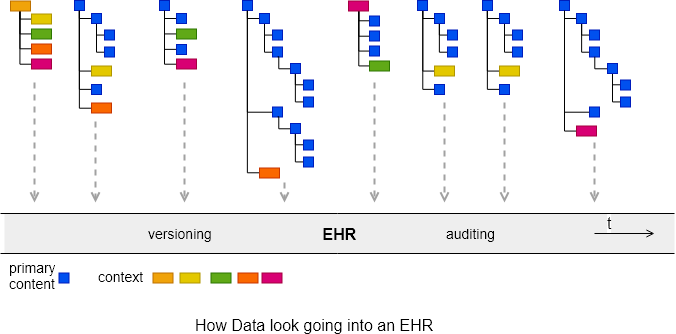
Getting the data out
Now let us consider what it means to get data out of an EHR. This may be done in various ways. Clearly, data can be read in the same chunks it was written. This relies on the reader application establishing (e.g. by earlier reads) the current context, i.e. episode, patient, department, care plan etc. This is very common for point of care applications, where data are being viewed in the form they were created, or close.
When it comes to extracting data in an ad hoc manner, things look rather different. The first thing is: any item of committed data may be queried hundreds or thousands of times, for different purposes, and in different result structures. Data consumers are all different, and there is no general recipe for what context information they want or need.
Native Retrieval
Any EHR or EMR system or product will include querying facilities, which may be SQL, data extraction (ETL) and reporting facilities. The platform I work on, openEHR, provides the Archetype Query Language, and REST APIs, which makes it possible to query any data based on the archetypes used to structure it. This makes it easy to retrieve fine-grained elements, e.g. the most recent blood sugar measurement, or large openEHR structures, e.g. a complete Observation or Composition. Regardless of the details, these facilities are native data retrieval methods that retrieve the data of the system / EHR in its native form, or a trivial transform or serialisation thereof. Such facilities are the normal ones to use within the system environment, and there is no loss or semantic barrier.
We can visualise native ad hoc data retrieval as follows.

Different factorings of the primary data and context are possible. If the result is intended to be stand-alone and represent most/all extant context, more context data elements can be brought back, attached to primary element(s). This might require the definition of some alternative model entities designed to wrap primary data with context items that were originally committed over time, in different commits. Regardless, the overall model architecture remains coherent, since retrieval doesn’t change it.
Generic Data Retrieval: Messages, Resources, Documents
Things change for generic data retrieval methods that extract data and convert it to a new data model. This is the primary use case of interoperability frameworks like EDIFACT, HL7v2, HL7 CDA and HL7 FHIR, which impose their own definitions of the data. The idea is that if everyone subscribes to the imposed definition, it becomes the effective lingua franca of larger environments containing mixed systems (although this sounds good, its utility is limited in practice, primarily due to weak semantic architectures of standards and mismatch to both producer and consumer environments – messages are like forcing a Spanish person to communicate to a German via Bahasa Malay. For these reasons, the main success of messages is in domains with very regular information of limited diversity, like lab and radiology. More on the message mentality here). The details of what retrieval looks like in various concrete technologies differs. In FHIR, the approach taken has been to define resources, each of which captures a small group of primary data elements, wrapped up with what is thought to be all possible context that might apply.
Like all message/document standards, FHIR imposes its own model of data and has no idea of primary information data structures in native systems. In fact its modelling of data is fairly limited with resources being close to unstructured bags of attributes. There is no inheritance at all (other than from generic resources like DomainResource), thus no reuse of data attributes common to related classes (e.g. Person, Practitioner, Patient). Some resources have some internal compositional structure and design, others almost none. Extracting data via FHIR requires the source system to convert the subset of data being requested to the structures of FHIR resources, or profiles thereof.
In most cases FHIR data look like one or a small subset of original primary data elements (e.g. just serum sodium or systolic BP) wrapped with all or most context data that supposedly applies (e.g. subject, encounter, referral, appointment, and so on). FHIR is thus a semi-structured data retrieval mechanism, and very different from an architected health data persistence mechanism. We might visualise FHIR data retrieval like this.

There is no doubt that FHIR has its uses and indeed being able to obtain a serum sodium or series of blood sugars from a closed EMR with a reasonable amount of context, in a standard way is useful.
It is currently unclear how standardised FHIR data will be though, since it is mostly defined by profiled versions of base resources, and the general trend so far (e.g. at simplifier.net) appears to be a proliferation of profiles that remove unwanted base resource elements and add arbitrary structure to represent the data needed by a particular use case. Thus, obtaining larger original structures requires the construction of profiles that try to mimic such structures. Standardising these would require a major modelling governance effort – similar to the grass-roots clinical modelling community created around the openEHR Clinical Knowledge Manager, which contains around 9000 clinical data points in 600 archetypes, created and maintained by 2200 clinical and health informatics professionals from 90 countries.
Building an EHR product from FHIR?
Given the semantic distance between FHIR and an architected HIS or EHR system, generating FHIR resource instances to faithfully represent non-trivial data in source system is in many cases going to be a challenge, and in some cases impossible (i.e. the FHIR result will be lossy).
For organisations thinking of trying to build an EHR system, FHIR (as HL7v2 and CDA) would be an inappropriate starting point. The use case it was designed for is getting data out of the EHR (and other types of HIS), not putting it in. As should now be clear, these two activities are not simple or symmetric opposites, but qualitatively different things.
A good EHR system is based on architecture that is designed around principles that relate to structured capture, persistence and native retrieval of data from original clinical situations. These include:
- versioning and commit auditing
- comprehensive information model of data types, general clinical and demographic structures, including structured model of the various contexts
- library of domain content definitions for O(10,000) clinical information structures – designed by clinical and health informatics experts (e.g. Intermountain Healthcare Clinical Element Models, HL7 CIMI archetypes, openEHR archetypes, and in an earlier technology, the VA/DoD FHIM)
- query language enabling domain-level query, report, ETL etc
- service model including generic CRUD and higher order services, embodying the transactional semantics of the system (e.g. based on a services ecosystem)
- content and service definitions for access control, privacy and consent
- terminology and reference data (medications etc) services;
- system access logging
- security features
Building a componentised service-based architecture on these principles is a non-trivial endeavour, not to be undertaken casually.
While it is unlikely that anyone thinks that FHIR does all of the above, one hears that FHIR is a (or maybe ‘the’) new solution for the information model, content definition library, querying and service model. Whilst it does contain some elements of these, it does not provide an architecture of any of them, in the sense required by an EHR.
Conclusion
FHIR is designed to get data out of (usually) opaque systems, optimised to retrieve one or a few primary data elements and most/all context as an unstructured list of attributes. The EHR on the other hand is a fully designed and architected component that takes into account all the semantics and structure of content and context of healthcare processes. FHIR is a poor fit as an architectural basis for an EHR, and the effort in trying to use it as such is likely to be greater than starting from scratch using principles and models available from the last 35 years of academic and industrial research and development in the area.
We would be better off concentrating on improving FHIR for the use cases it was designed to serve, and considering how best to connect that to existing and emerging EHR architectures and platforms.


I agree, FHIR and EHR are totally different things. I’m focusing on FHIR as a communications conduit between hospitals and facilities. Say, a patient is transferred from a hospital to transitional care. Their details may be transferred via FHIR or an ambulance may transfer patient details to an ED prior to arrival. I’m looking at a raid-like interface between the hospital’s database and a FHIR server.