
In this post I document further observations on the FHIR resources, made during the transcription of the DSTU4 FHIR resources to the BMM format used in openEHR, as described here. This post examines the definition of process state in FHIR resources.
FHIR contains a number of resources that represent workflow actions in healthcare, including ServiceRequest, MedicationRequest, MedicationDispense, Appointment and so on. All of these contain a ‘status’ attribute which is coded with a local code-set representing possible lifecycle states of the action. Here is ServiceRequest:
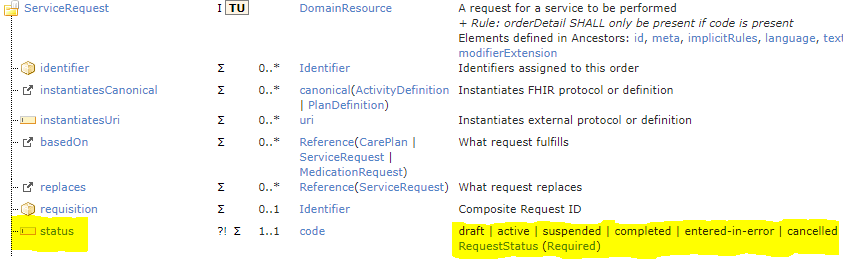
The first problem is that the states ‘draft’ and ‘entered-in-error’ are to do with documentation lifecycle, whereas the other states (active, suspended, completed, cancelled) are to do with the clinical activity in real life. These are two state machines mixed into one. ‘Draft’ and ‘entered-in-error’ will never be sensible states of a Service request being performed.
We can also compare lifecycle states defined for various resources (here
ServiceRequest, MedicationRequest, MedicationDispense, Appointment):
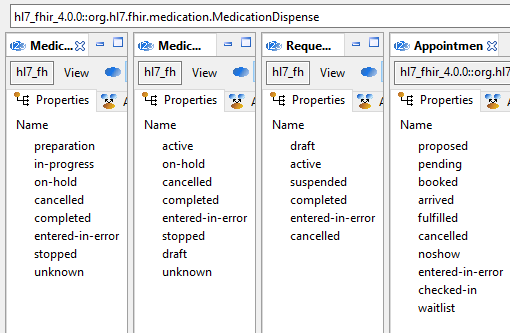
What we see here is that each type of activity has its own lifecycle states, and implied transitions. This is not unexpected, since there is no reason why (for example) appointment would not have a ‘noshow’ state, whereas this makes no sense for MedicationRequest. The problem here is that there are around 20 distinct state machines, all different, implied by the various status attributes. To be represented in software, each would require its own implementation, if indeed ‘state’ were to be properly represented as a type. In FHIR-land, it is unlikely that anyone will attempt to implement state machines, when simple flat code lists will do.
The next question is how these state machine vocabularies are known to accurately represent the lifecycle states of the various kinds of activities in any or all legacy systems being modelled by FHIR resources, since resources are developed by committees presumably making best guesses as to processes that really occur inside EMR systems of which they are likely to have only partial knowledge. Additionally since they are using the 80/20 rule as a filter, it will be the case that FHIR resource state machines will be approximate matches for numerous different process workflows in reality.
It is an additional question how all these specific states would be reliably derived by all developers in the same way from the data held by the real systems to which their FHIR adapters connect. Whether there is even one EMR product out there that contains exactly the set of states for any of these kinds of requests is doubtful, but it is certain that in general, generation of the state values from multiple systems will be done in multiple different ways in private adapter implementations, with limited hope of reliable interoperability across the different implementations.
A further assumption for representing process state accurately on the FHIR client side is that the status field is actually read every time the relevant data are accessed. To obtain changes in state, either push notification or polling has to be used.
Given that the state machine vocabularies are committee best guesses in the first place, and given that the generation of data values from a multitude of real source systems will be an additional set of often differing best guesses by hundreds or thousands of implementers as to how to interpret the source data, even assuming that the status field is being read correctly over time, it is unlikely to be reliable for generating notifications, alerts or reports.
One might ask: how should we go about doing state machines then? This is after all a tough problem. One approach is the one we use in openEHR, which is to define a standard ‘instruction’ state machine, at a relatively abstract level (‘instruction’ is the openEHR term for ‘order’ or ‘request’). This is shown below:
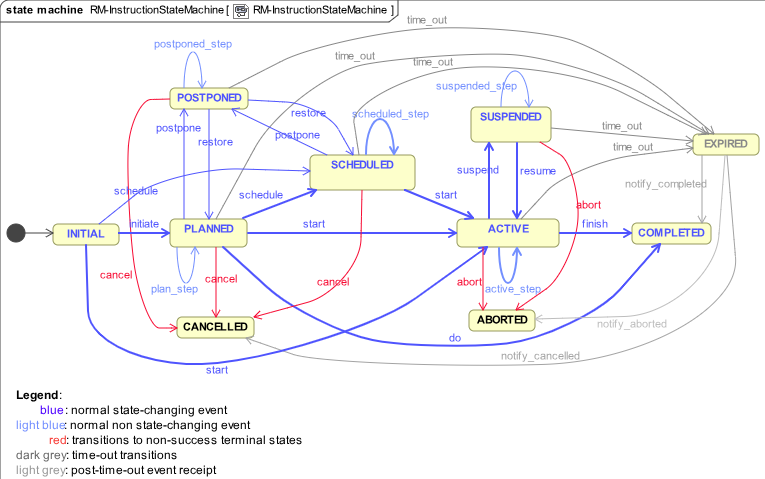
openEHR then provides a way to map specific workflow steps (the equivalent of the 20+ different state machine vocabularies in FHIR) to the states. This is done via archetypes in openEHR, exemplified by the CKM MedicationManagement ACTION archetype:
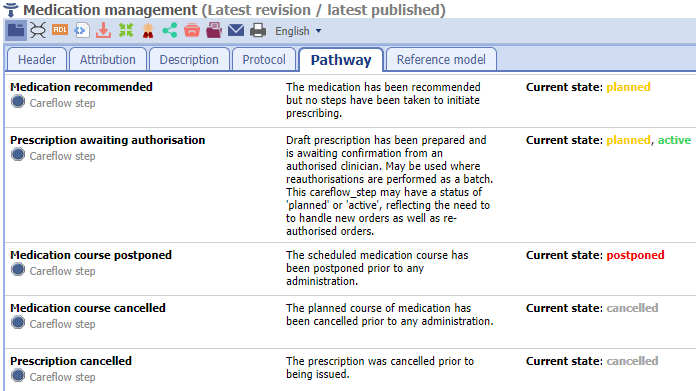
In the above, action-specific steps on the left are mapped to standard state machine states on the right. The openEHR state machine is a slightly adapted version of models published in literature, and has been used in the above fashion for over a decade.
This method provides a basis for standard processing, and if used in FHIR would also make it much easier to synthesise the state values from data, due to the limited number of states, and particularly due to ability to map the ‘active’ state to many fine-grained states. In openEHR systems, even though the ‘careflow steps’ mentioned in archetypes are necessarily somewhat approximate (as in FHIR,), the standard state machine states are very reliable. This enables applications to make generalised reliable queries across all outstanding orders, requests etc, e.g. to determine what is currently active, suspended, planned etc.
An equivalent of this approach could be developed for FHIR without much trouble. A more effective approach is then possible for defining specific state machines. Instead of trying to standardise abstract types of request, the process steps for concrete back-end systems can be specified as and when encountered. For some well-known systems or applications, such as appointments in e.g. Cerner Millennium, Intersystems HealthShare etc, the definition can be worked out just once and published centrally. For in-house systems it will be worked out locally and correctly by people who know those systems.
The big difference with this approach is that as long as the concrete steps (i.e. ‘booked’, ‘on-hold’, and ‘cancelled’ etc) are mapped correctly to the abstract state machine states (planned, scheduled, postponed, cancelled, active, suspended, aborted, completed, expired), and the latter are used by client applications, then reporting of what processes are ‘active’, ‘completed’ etc for a patient will be far more accurate. This is usually easy because the abstract state machine has a small number of ontologically distinct states with clear definitions e.g. ‘active’ corresponds to any process step that leaves the process still executed; ‘aborted’ means a running process that has been permanently stopped, and so on.
In summary, the following changes are proposed:
- separate the documentation lifecycle from the real-world service request state machine – this disentangles pseudo-states like ‘draft’ and ‘entered-in-error’ from states of real processes (a dedicated attribute could be defined for documentation lifecycle state if needed);
- define and use a standard state machine for the status attribute;
- add another attribute that optionally reports local concrete process ‘steps’ to be specified in profiles;
- perform all client-side application processing with the status attribute, i.e. the standard state machine states.
This would bring the following advantages:
- there would be only one standard state machine for all FHIR ‘request’ type resources (it could easily be the same as the openEHR state machine, which has no ‘openEHR’ specificity at all); this would be documented in one place for all of FHIR;
- request-specific state machines for different request types do not have to be modelled at all in HL7 committees making rough guesses – the status field would instead always be populated by the vocabulary of the standard state names;
- request-specific ‘steps’ (the current FHIR status vocabularies) would by replaced by local server-side ‘steps’, mapped to the standard states;
- client-side reporting, notification based on process state would be more accurate.
In other words, less work, more quality.

