

There are some rather obscure definitions of health IT’s favourite term interoperability floating around, for example:
Continue readingThere are some rather obscure definitions of health IT’s favourite term interoperability floating around, for example:
Continue reading
The above shows a typical web form calculator for the CHA2DS2-VASc score, used for estimating the risk of stroke in patients with non-rheumatic atrial fibrillation (AF), primarily for the purpose of deciding the use of anti-coagulant therapy [Wikipedia].
How would such a score be programmed?
Continue reading
Another bit of software engineering knowledge from my archive relates to two well-known formal quality methods used in software development. This is from a presentation made at ETH Zurich in 2010.
Continue readingHere’s an infographic (alright, it’s just a diagram) I created over a decade ago, randomly extracted from the archives. I think it’s almost self-explanatory.

Here’s a few more slides using this. I wouldn’t adjust too much today, but note that devops and continuous integration had not assumed the importance they have today.
Continue reading
Nominalism is a philosophical doctrine usually understood to entail a rejection of universals, in favour of the belief that only the concrete exists. Universals are understood as instantiable entities, i.e. something like types. Another flavour of nominalism involves rejection of abstracta, such as mathematical entities, propositions, fictional entities (including possible worlds). You may read about them in the SEP’s rather dull entry on Nominalism in metaphysics.
Continue readingSometimes a graphic is worth more than words. This is an attempt to capture all the salient features of multi-level modelling, the openEHR way. See the openEHR primer for the story.

Although this is ‘our way’ of doing it, I contend that the general scheme is universally needed – see the bullet list after the cartoons in this older post on openEHR for HL7 FHIR users.
Comments welcome.

How close can we get to making a clinical decision logic language look like the published guidelines which it is used to encode?
Below is an openEHR Decision Logic Module (DLM) example, in the current form of the openEHR Decision Language specification currently under development. Why another language? Well I’ll answer that with: show me a language that does this, and we’ll use it instead (e.g. why not ProForma, Arden, GLIF etc?).
Of course this language doesn’t yet solve all the problems, but we are taking two particular challenges seriously:
As background, our conceptual basics here.
Continue reading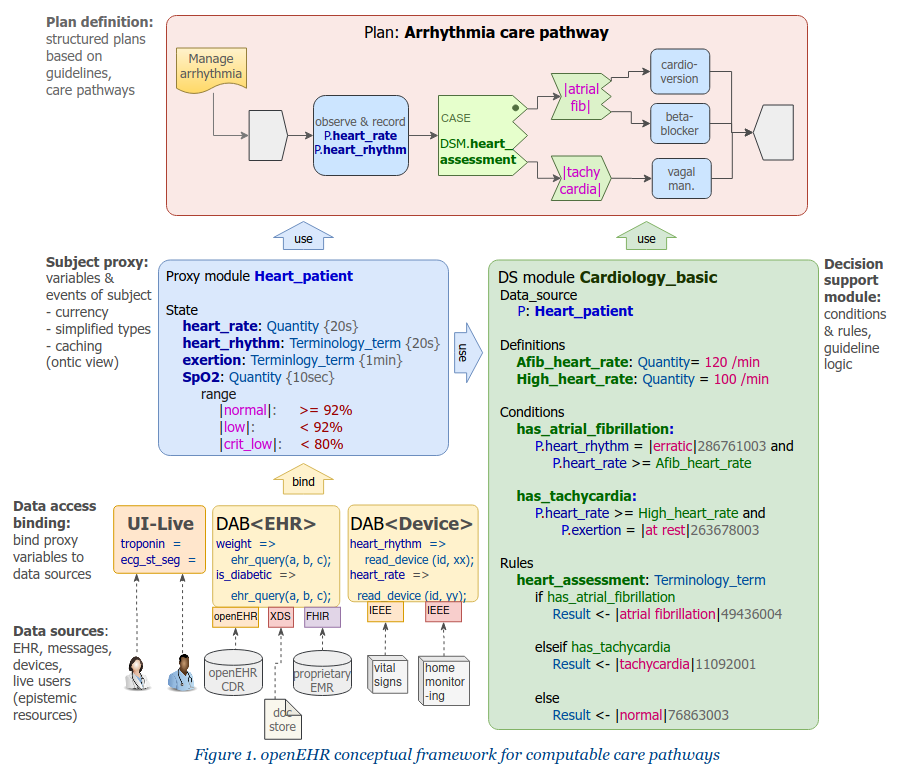
Why don’t we have widespread clinical decision support (CDS), computable guidelines, clinical workflow (plans), and why don’t the pieces we do have talk to the health record? The first time I heard such challenges framed was around 2000, and even at that moment there were experts who had been working on modern versions of the problem for at least a decade, not to mention earlier generations of ‘classical’ AI systems such as MYCIN. So it’s not for lack of time.
After 20 years of staying out of this particular kitchen, I took the plunge in 2015, with a number of projects including Activity-Based Design at Intermountain Healthcare, a major openEHR development project called Task Planning (partly funded by Better.care in central Europe and DIPS in Norway), as well as some minor involvement in recent OMG BPM+ activities. We already had within the openEHR community the Guideline Definition Language (GDL), a fully operational decision support capability originally developed by Rong Chen at Cambio in Sweden (resources site). This provided us with a lot of useful prior experience for building a next generation combined plan/guideline facility.
Here I will talk about what I think has been conceptually missing for so long.
Continue readingI have posted before on the FHIR ‘choice’ construct, particularly here, where I have explained the problems of the choice construct (essentially: it’s an ad hoc constraint construct that subverts the type system, and doesn’t belong in typed formalisms; none use it, except XSD, well known as a poor formalism of little use for modelling). In this post I look into the details of the problem and some possible solutions.
Much of what I report here is connected to discussions I have participated in on the FHIR zulip site, methodology stream.
TL;DR spoiler: the main analysis here.
Continue reading
One of the principal reasons for why I and others are proposing (some) type hierarchy in the FHIR Admin resources is as follows (my earlier post on this). Working Groups (i.e. committees) building Resources are currently in the situation of defining Elements in a Resource, i.e. defining name, type, cardinality etc. The Resources are a typed system. Now, in places where Reference() is used, typing is being subverted; they are no longer stating a necessary type, they are trying to think of all possible use cases, and stating a corresponding list of types of instances in those use cases.