I started working in the Health IT area in 1994, on a major European Commission funded project. I attended years of standards meetings at HL7, CEN and occasionally OMG and ISO from 1999 to about 2012. And I’ve observed the constant failure of standards (through inappropriate hopes and expectations) to provide anything like a sustainable solution for interoperability. Here are the lessons I draw from this.
- Premise #1: interoperability is an outcome, i.e. an emergent quality, not a created input. You can’t achieve true (automatic) interoperability by trying to engineer for it after the creation of the systems you want to interoperate. Why? Because interoperability happens at the touchpoints between parts of a system. To achieve it, you have to have a) knowledge of and ideally b) some say in the architecture of those components – only then will you understand how to create interoperability at the interfaces in question.
- Premise #2: de jure standards should not be mistaken for architecture. Today’s HIT standards are attempts to engineer post hoc interoperability with no knowledge of the system components – they are essentially various forms of message on the wire. The result is O(10,000) mutually inconsistent interoperability points, not an interoperability-enabled architecture. Bureaucrats routinely mistake standards for architecture, saying things like ‘we must base our system on standards x, y, z’, or ‘we’ll design the system based on standards’. Only do that if you want to repeat the cycle of death.
- Conclusion #1: any large healthcare delivery organisation or environment has no choice but to define its own architecture, which means thinking about its own data, processes and knowledge assets – in depth. The outline of how interoperability will be achieved at any interface point must be part of that architecture. Only then can any published standard be considered for use, if it truly fits and provides a language of interchange that will be in wide use for the same purpose.
- Conclusion #2: the only way to engineer standards that will result in sustainable interoperability is to define an open architecture. ‘Standards’ will just be pieces of that specification that apply at interface points.
There is a hidden requirement for success, which is as follows:
- Requirement: to achieve interoperability, common knowledge resources must be defined and used across the entire domain – i.e. ontologies, terminologies, definitions and models of higher-level artefacts such as data sets and guidelines.
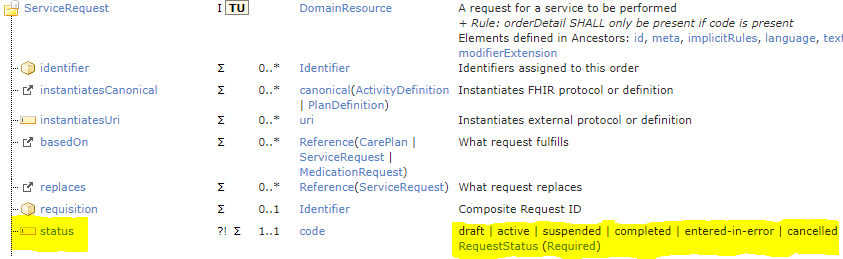
With respect to this point, the Health IT domain has already achieved quite a lot at the terminology level; has good de facto standards for shared data sets (openEHR archetypes, Intermountain Healthcare Clinical Element Models, although the SDOs still struggle with the approach); is only just starting to understand ontology; and is making some initial progress in the process and guideline domain. Most of these are still poorly integrated, but the direction is clear.
The details of how to engineer for sustainable interoperability are mostly outlined in this previous post.
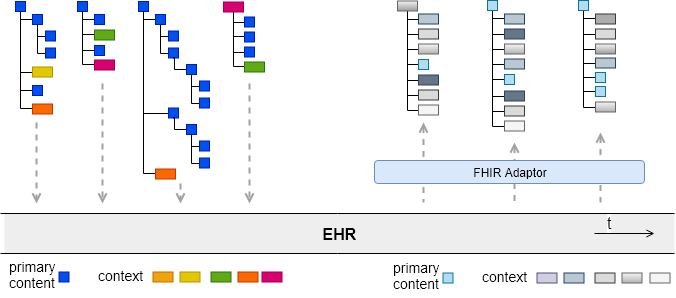
The underlying lesson is to recognise that any environment in which interoperability is desired is a complex system, operating on multiple hierarchical levels, with emergent properties at each. Interoperability is one of those properties.